1. 시작하면서
이전 글에서는 Redis를 활용하여 서버의 응답시간을 개선해봤습니다.
https://gamxong.tistory.com/161
[소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 2편
1. 시작하면서이전 글에서는 OOM 문제를 해결하면서 메모리 사용량에 집중해봤습니다. 2025.03.08 - [BE/Spring] - [소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 1편 [소프티어] 5만건 데이터, OO
gamxong.tistory.com
소프티어 활동이 끝나고 더이상 무료서버도 사용할 수 없게 되었습니다.
서버 이전 작업을 진행하던 중, 팀원의 도움으로 우수한 사양의 서버를 무료로 사용할 수 있게 되었습니다.
그 과정에서 생겼던 아키텍처의 변화와 조금은 불필요하지만 호기심에 진행했던 성능개선에 대해 소개드리고자 합니다!
2. Redis에서 로컬캐시 Caffine으로
앞 선 설명처럼 팀원의 도움으로 고성능 서버를 무료로 사용할 수 있는 기회를 얻게 되었고, 이를 계기로 캐시 전략에도 변화를 주게 되었습니다.
기존 Redis 기반 캐시 구조는 서버의 메모리 사용량과 서버 확장성을 고려해 선택된 아키텍처였습니다.
하지만 단일 서버의 스펙도 굉장히 좋아져 메모리 사용량의 부담이 줄게 되었고, 결국 scale-out 관련해서도 진행하지 않았습니다.
추가로 서버 확장 가능성도 낮아진 상황에서, 별도의 외부 캐시 서버(Redis)를 사용하는 것은 오히려 불필요한 네트워크 오버헤드로 작용할 수 있다고 생각했습니다.
또한, 더 높은 TPS를 달성하기 위해선 네트워크 지연이 없는 로컬 캐시의 도입이 더 적합하다고 판단했습니다.
2-1. EhCache vs Caffeine, 왜 Caffeine을 선택했는가?
로컬 캐시 라이브러리로는 대표적으로 EhCache와 Caffeine 두 가지를 검토했습니다.
하지만 저희가 필요로 하는 기능은 복잡한 기능이 아닌 단순하고 빠른 캐싱 기능이었고, 성능이 가장 중요한 우선순위였습니다.
- EhCache는 기능이 풍부하지만 상대적으로 무겁고 구성도 복잡한 편입니다.
- 반면 Caffeine은 Google Guava의 후속으로 만들어진 고성능 캐시 라이브러리로, JVM 기반 애플리케이션에서 가장 빠른 캐시 구현체 중 하나로 평가받고 있습니다.
실제로 여러 벤치마크에서도 Caffeine은 높은 hit rate와 낮은 latency를 보여주며 성능 면에서 매우 우수한 결과를 보이고 있습니다.
따라서 저희는 Caffeine 캐시를 사용하기로 했습니다.
추후에는 Caffeine + Redis 조합으로 1차는 local cache (Caffeine), 2차는 distributed cache (Redis)로 구성해보는 구조도 검토해볼 예정입니다.
3. Caffine 도입
로컬 캐시는 예전부터 글로벌 캐시(예: Redis)에 비해 네트워크 비용을 줄일 수 있다는 장점으로 잘 알려져 있습니다.
하지만 로컬 캐시의 진짜 강점은 단지 네트워크 비용 감소에만 그치지 않습니다.
3-1. 객체 재사용에 의한 메모리 효율
로컬 캐시는 데이터를 서버 메모리에 직접 저장하기 때문에, 매 요청마다 객체를 새로 생성할 필요 없이 이미 저장된 객체를 재사용할 수 있습니다. 이는 고성능 서버 환경에서 메모리 사용 효율을 크게 개선시킵니다.
예를 들어 보겠습니다.
총 10MB 크기의 객체를 1MB 단위로 불러와 계산하는 로직이 있다고 가정합니다.
이 로직을 단일 스레드에서 한 번 수행하면 총 2MB의 메모리를 사용하게 됩니다.
Redis 기반 캐시
- 매 요청마다 Redis에서 객체를 불러올 때마다 새로운 객체가 생성됩니다.
- 1개의 요청: 2MB 메모리 사용
- 100개의 동시 요청: 200MB 사용 (2MB × 100)
→ 객체가 매번 새로 생성되기 때문에, 요청 수가 많아질수록 메모리 사용량이 급증합니다.
로컬 캐시 (Caffeine)
- 자주 사용하는 10MB 객체는 서버 메모리에 이미 캐싱되어 있음
- 1개의 요청: 캐시된 10MB 객체 + 계산에 필요한 1MB → 총 11MB
- 100개의 동시 요청:
- 캐시된 10MB는 공유
- 계산을 위한 1MB × 100 → 총 110MB 사용
→ 객체를 재사용하기 때문에, 같은 키에 대해 많은 요청이 있을 경우 전체 메모리 사용량이 훨씬 적습니다.
요약
| 항목 | Redis | 로컬 캐시 |
| 객체 재사용 | 매 요청마다 새 객체 생성 | 메모리에 저장된 객체 재사용 |
| 단일 요청 메모리 | 2MB | 11MB |
| 100개 동시 요청 메모리 | 200MB | 110MB |
3-2. 성과
서버 스펙이 증가한 만큼 기존 부하 vUser 50에서 vUser 100으로 늘린 후 진행하였습니다.
기존 Redis 방식
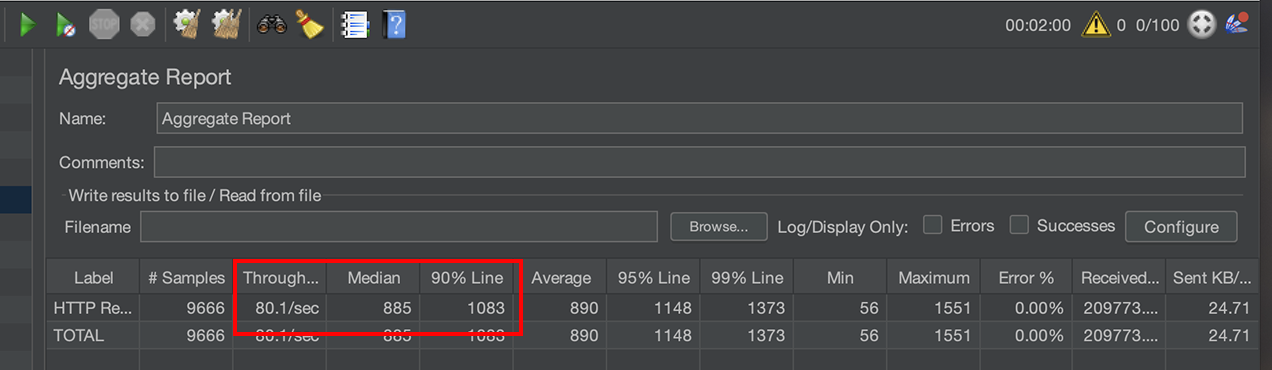
TPS : 80
P50 : 885ms
P90 : 1083ms
Caffeine 방식
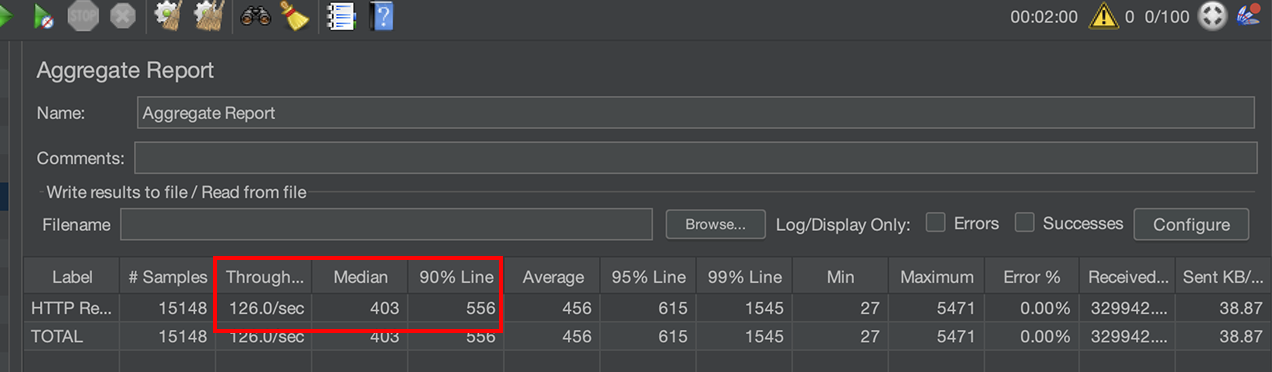
TPS : 80 -> 126 개선
P50 : 885ms -> 403ms 개선
P90 : 1083ms -> 556ms 개선
이처럼 네트워크 비용 절감과 객체 재사용 덕분에, 단순히 캐시 방식만 변경했을 뿐인데도 무려 50%의 성능 개선을 이룰 수 있었습니다.
4. Log4j2 비동기 로깅
4-1. 로깅이 문제가 될 수 있다?
생각보다 오래걸린다..?
하지만 서버 성능이 눈에 띄게 향상되자, 점점 더 욕심이 생기기 시작했습니다.
특히, 로컬 캐시를 적용했음에도 응답 시간이 여전히 400ms 대에 머무르는 이유가 잘 이해되지 않았습니다.
이왕 여기까지 온 김에, 실무에서 괜찮은 성능이라고 판단하는 두 자릿수(ms) 응답 시간까지 직접 도달해보고 싶어졌습니다. 그래서 과연 어디서 병목이 생기는지 면밀히 관찰해봤습니다.
처음에 생각했던 것은 비즈니스 로직에 문제가 있을까 생각이 들었습니다. 왜냐하면, 저희가 캐싱된 데이터를 단순히 서빙하는 것이 아닌, 내부적으로 복잡한 계산로직을 거치게 됩니다. 그래서 해당 로직의 소요시간 AOP를 통해 측정해봤습니다.
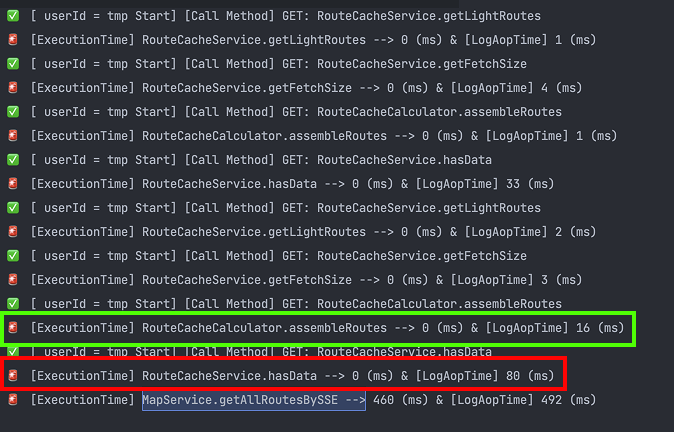
각 라인마다 2가지 종류의 시간이 있습니다.
- [왼쪽 시간] : [해당 로직의 실행시간]
- [오른쪽 시간] : [왼쪽시간] + [관련 로그를 출력]
가장 하단의 492 ms 는 해당 로직의 총 소요시간입니다.
그리고 초록색 박스는 앞서 얘기한 "복잡한 계산로직"의 소요시간입니다. 예상과는 다르게 1ms 미만에 처리가 되는 것을 확인할 수 있습니다.
하지만 로그를 출력하는데 걸린 시간은 아래와 같이 굉장히 오랜 시간이 소요된 것을 확인할 수 있었습니다.
- 초록색 박스에서는 16ms(16ms - 0ms)
- 빨간색 박스에서는 80ms(80ms - 0ms)
- 마지막 라인에서도 32ms(492ms - 460ms)
4-2. 로깅을 하지 않으면 어떻게 될까?
그래서 기존의 로깅 로직을 전부 제외하고, 부하 테스트를 진행해봤습니다.
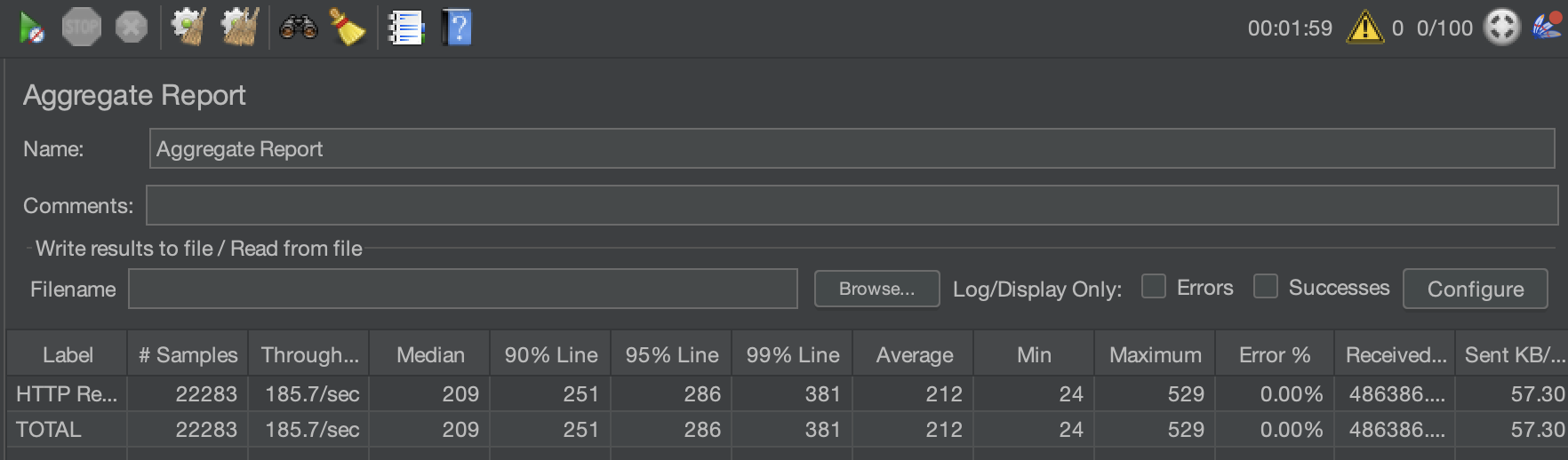
TPS는 126 -> 185로 개선되었고, 응답시간도 약 100% 개선이 되었습니다..!
하지만..!
실제 서비스를 운영하면서 관련 로그를 남기지 않는 것은 매우 위험한 일이라고 생각합니다.
문제가 발생했을 때, 정확한 원인을 파악하기 어려워 대응이 늦어질 수 있기 때문입니다.
이러한 관점에서 볼 때, 현재 로깅은 정말 필요한 로깅만 한다고 생각했습니다.
따라서 로그 자체는 줄일 수 없다고 생각하고, 다른 방식으로 접근했습니다.
4-3. System.out 은 syncronized 이고, log.info는 아니다?
대부분의 블로그를 봤을 때, 보통 System.out.println 방식이 아닌 log.info 방식으로 하는 것을 권장합니다.
다양한 이유가 있겠지만 그 중 항상 System.out.println 은 syncronized 블록이 있어 병렬요청 때 병목이 발생할 수 있다는 것입니다.
이 말은 마치 log.info 방식은 syncronized 키워드를 사용하지 않는 것으로 오해할 수 있다고 생각합니다.
(사실 제가 이렇게 오해하고 있었습니다만..)
하지만 실제로 Log4j2도 내부적으로는 thread-safe하게 동작하기 위해 필요한 부분에서 synchronized 나 그에 준하는 동기화 구조를 사용합니다.
Log4j2 기준으로 log.info 의 구체적인 동작은 아래와 같습니다.
1. 먼저 Log4jLogger 가 AbstractLogger 의 logIfEnabled() 메서드를 호출합니다.

2. AbstractLogger 에서는 로그 메세지를 만들고, 재귀 검증 후에 Logger 의 log() 메서드를 호출합니다.

3. Logger 에서는 전략패턴으로 현재 로깅 전략에 맞는 클래스를 호출합니다.
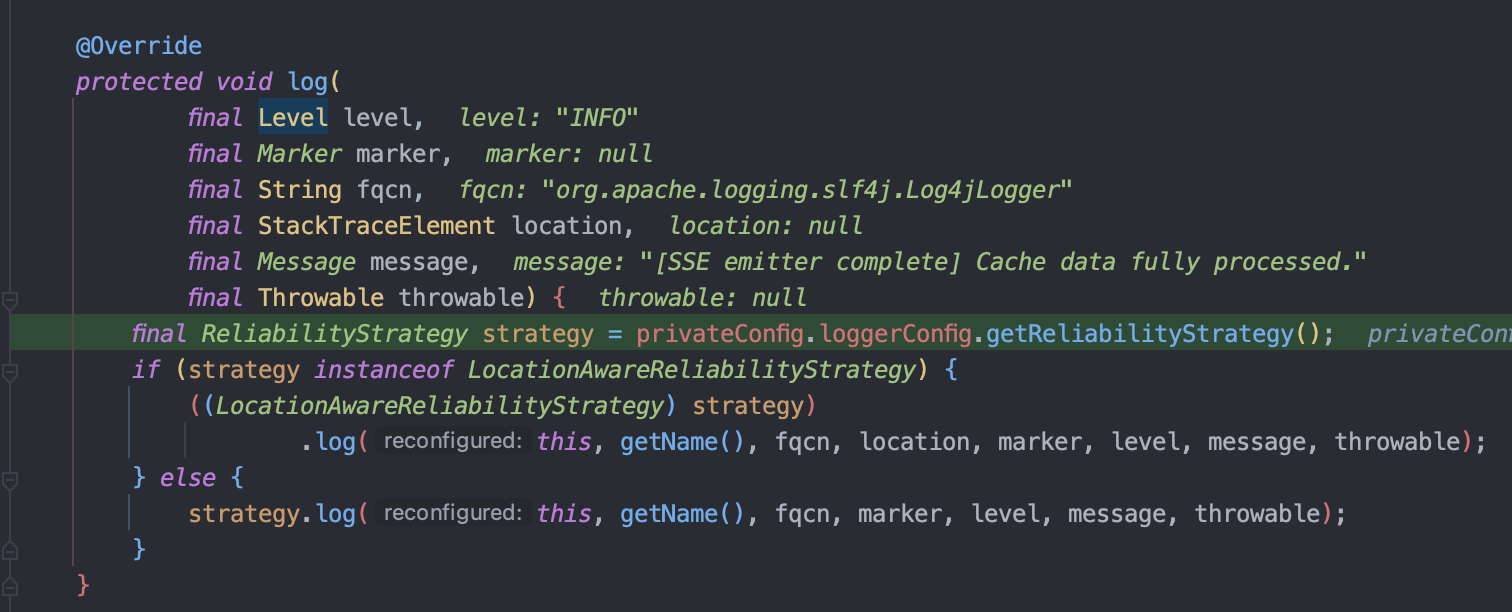
4. 각 클래스에서 관련 config 설정을 하여 LogEvent 를 생성한 후
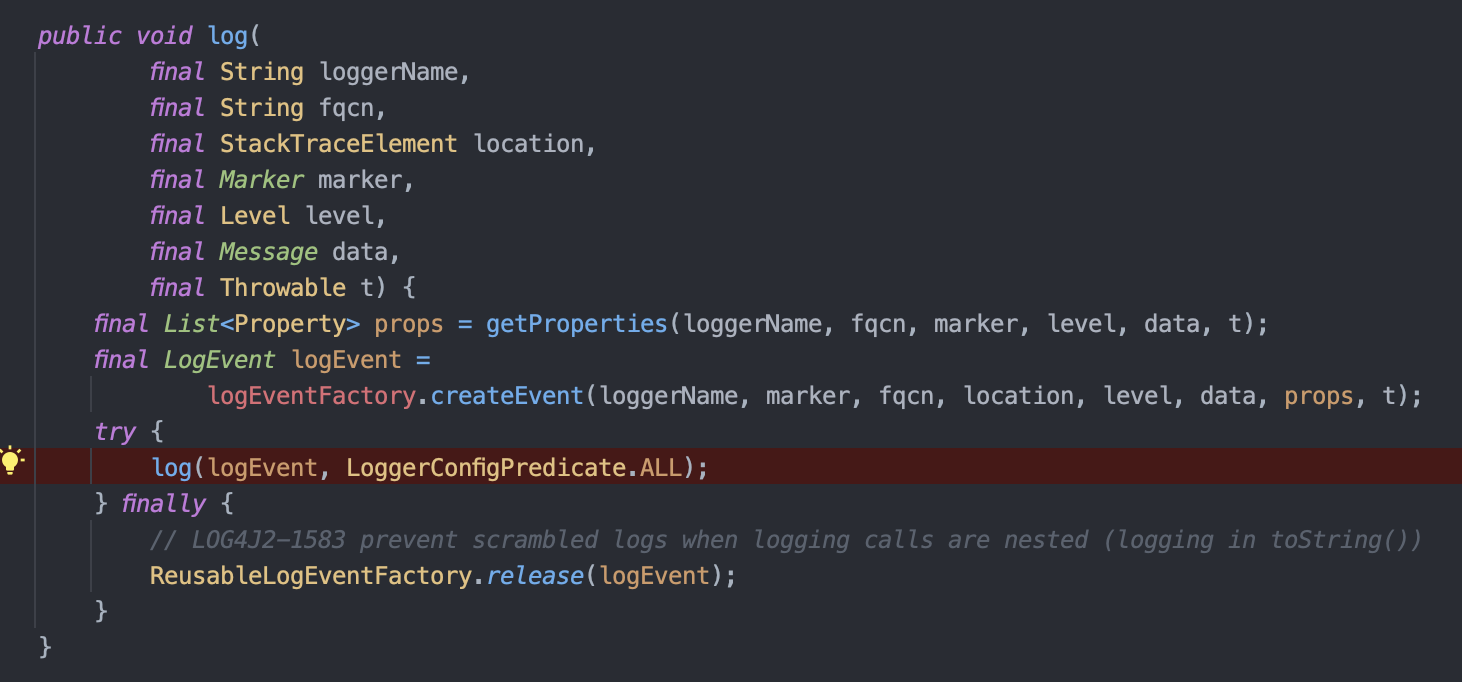
5. 해당 이벤트를 Appender로 이벤트 전달합니다.
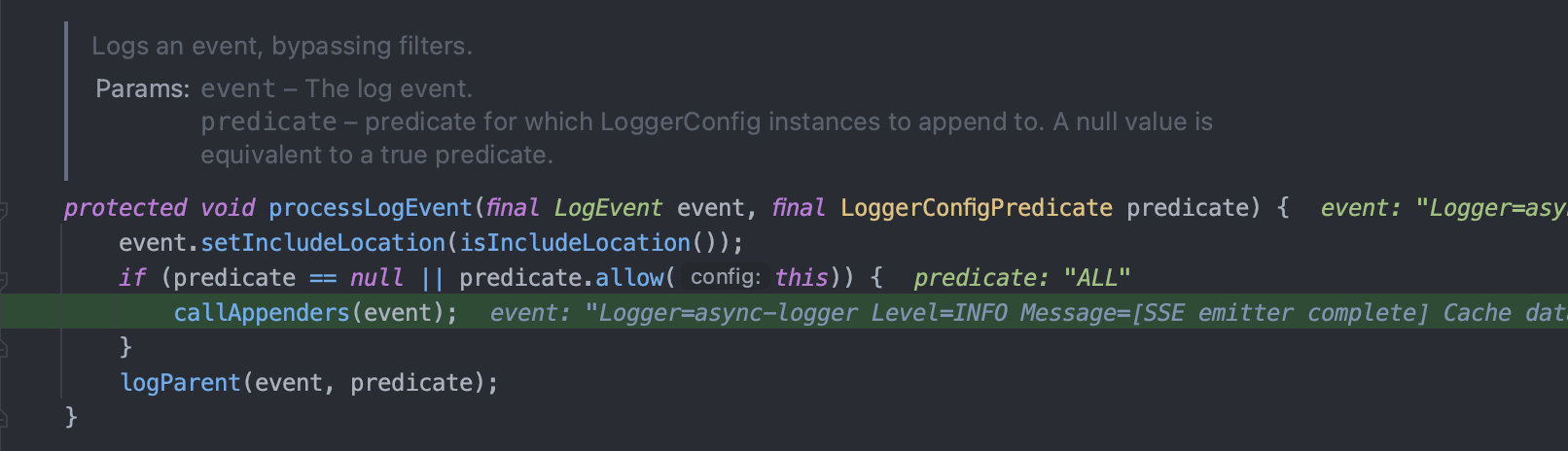
6. 이 시점에서 Appender는 출력 대상 (Console, File, Socket 등)에 따라 적절히 처리하는데, 예를 들어 콘솔일 경우 ConsoleAppender → OutputStreamManager를 통해 System.out에 출력합니다.
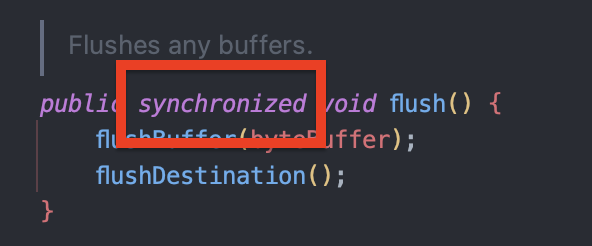
여기서 OutputStreamManager는 synchronized 블록을 사용해서 스레드 안전하게 System.out.write()를 호출합니다.
즉, ConsoleAppender는 내부적으로 동기화되어 있어서, 동시 출력 시에도 충돌이 발생하지 않도록 보장합니다.
4-4. 비동기 로깅 도입
결국 많은 요청들이 서로 콘솔에 로그 메세지를 출력하다보니 병목현상이 발생하여 400ms 응답시간이 나오게 된 것입니다. 그래서 이 문제를 해결하기 위해 비동기 로깅 방식을 도입해봤습니다.
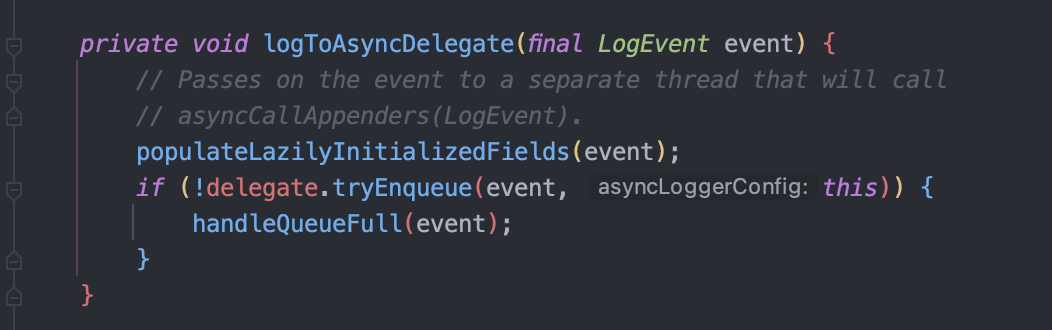
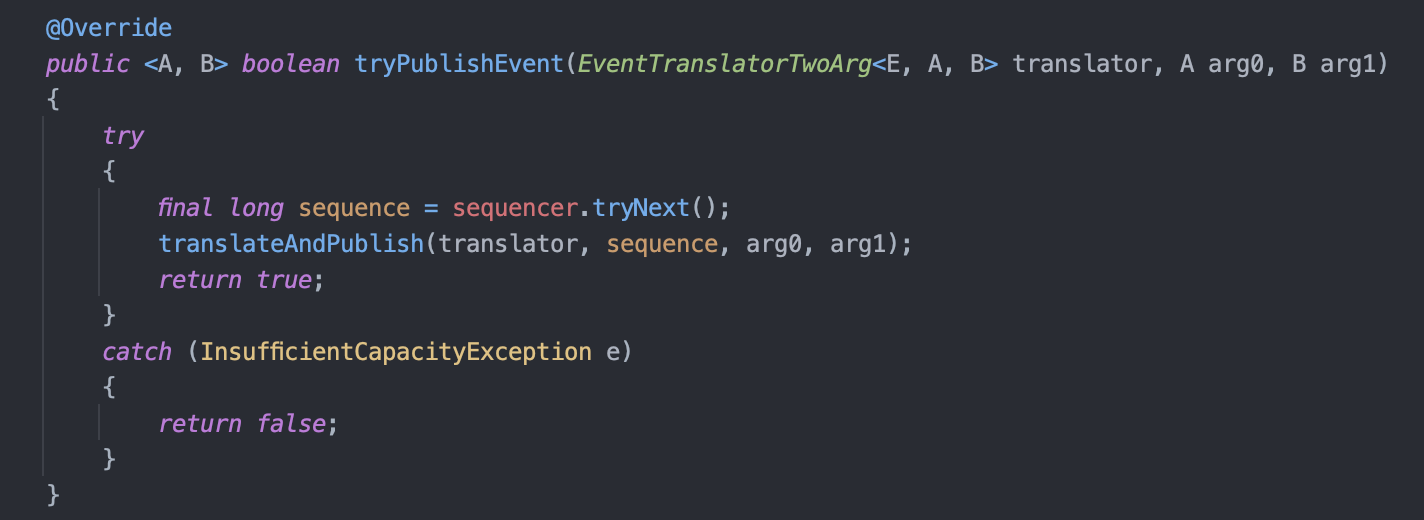
비동기 로깅은 Queue를 활용하여 구현되어 있습니다.
방금 전에 봤던 로깅 동작 과정에서 로그 이벤트를 Appender에게 전달하는 클래스를 오버라이딩하여 Appender를 직접 호출하는 것이 아닌, 아래 코드와 같이 Queue에 해당 이벤트를 넣고 publish 하게 됩니다.
이후에 백그라운드로 돌아가고 있는 Log4jEventWrapperHandler가 해당 요청을 받아 [6번 과정]을 거쳐 동기식 로깅과 동일하게 출력하게 됩니다.
이렇게 구현하게 되면, 결국 로깅 관련된 처리는 백그라운드 스레드에서 비동기적으로 처리되며, 메인 애플리케이션 스레드는 로그 출력이 완료될 때까지 기다릴 필요 없이 즉시 다음 작업을 수행할 수 있게 됩니다.
이를 통해 로깅으로 인한 응답시간 지연을 최소화시킬 수 있게 됩니다!
실제 적용된 비동기 로깅 방식을 살펴보면, 아래 처럼 비동기적으로 동작하는 것을 확인할 수 있습니다!
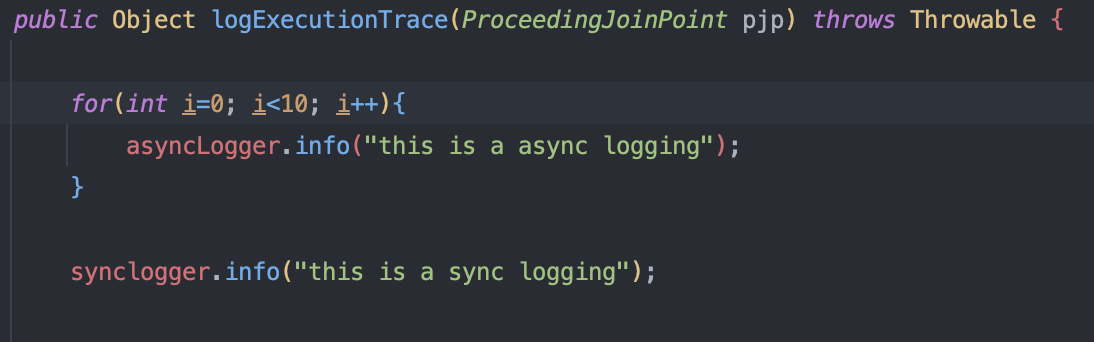
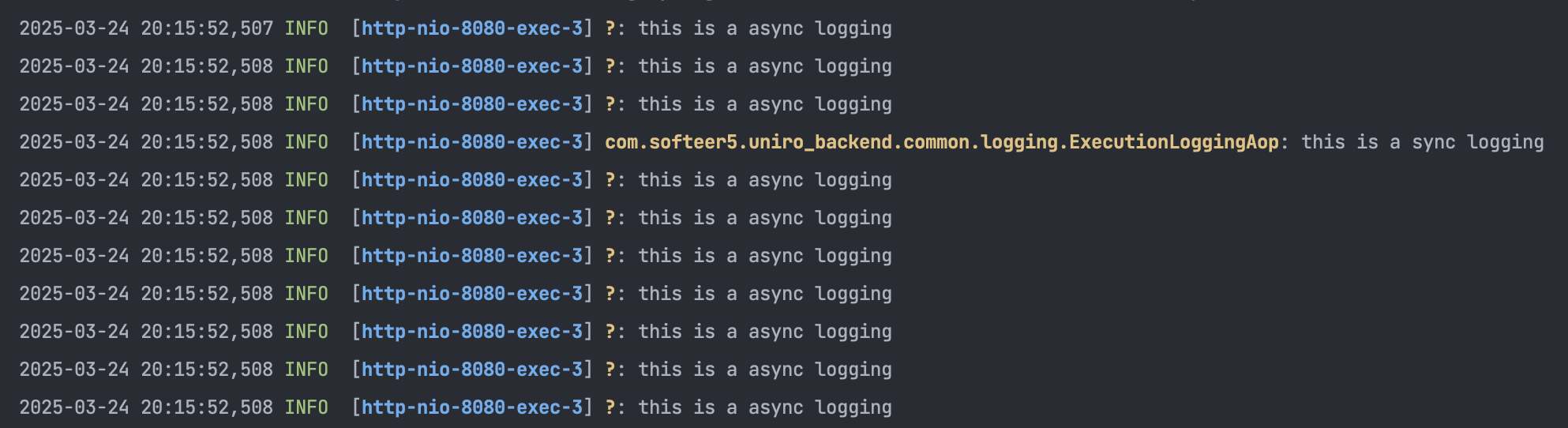
4-5. 성과
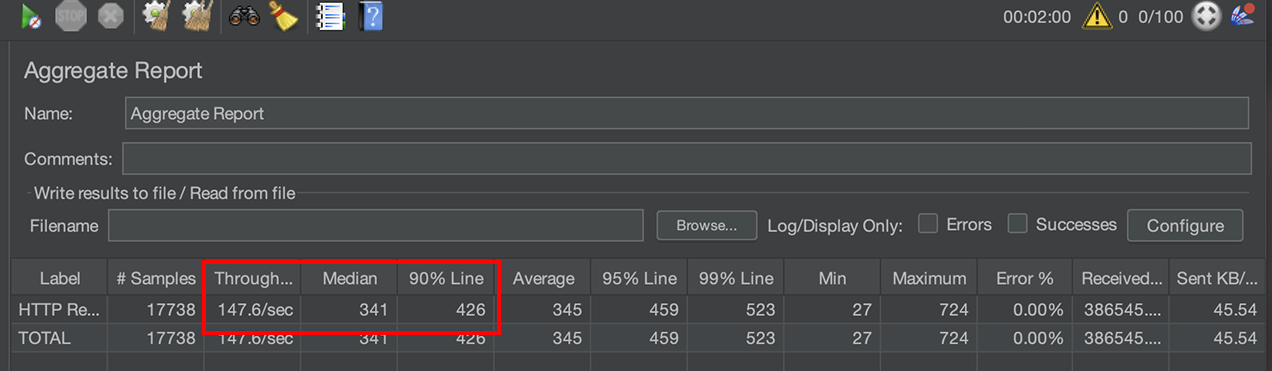
TPS : 126 -> 147 개선
P50 : 403ms -> 341ms 개선
P90 : 556ms -> 426ms 개선
로깅 기능 자체가 무거운 작업은 아니기 때문에 드라마틱한 성능 개선을 이루진 못했습니다.
하지만 로깅의 자세한 동작 과정을 알 수 있었고, "로깅도 병목의 원인이 될 수 있다"는 인사이트를 얻었습니다!!
5. Fastjson을 통한 직렬화 로드 감소
이러한 작업들을 거쳤음에도 불구하고, 여전히 300ms대의 응답 속도가 측정되고 있었습니다.
서버 내부적으로 300ms 이상 소요되는 로직이 있는지 확인해보았지만, 제가 작성한 서비스 로직 내에서는 응답까지 300ms 이상 걸리는 구간을 찾을 수 없었습니다.
그렇다면 병목은 과연 어디에서 발생하고 있는 걸까요?
이 시점에서 문득 지난번 2편에서 다뤘던 직렬화/역직렬화에 대한 아이디어가 떠올랐습니다.
Redis에 데이터를 저장하거나 불러올 때 직렬화/역직렬화가 필요했던 것처럼, HTTP Response 메시지를 클라이언트로 전송할 때도 직렬화 과정이 필수적입니다.
이 과정에서 사용하는 직렬화 도구에 따라 성능 차이가 발생할 수 있다고 판단했습니다.
예를 들어, 기본적으로 많이 사용되는 Jackson 대신 Fastjson을 사용한다면, 더 빠르게 직렬화 작업을 처리할 수 있을 것이라는 가설을 세웠습니다.
이에 따라, 간단한 실험을 통해 HTTP Response 직렬화 시 Jackson과 Fastjson의 성능 차이를 비교해보았습니다.
5-1. Jackson
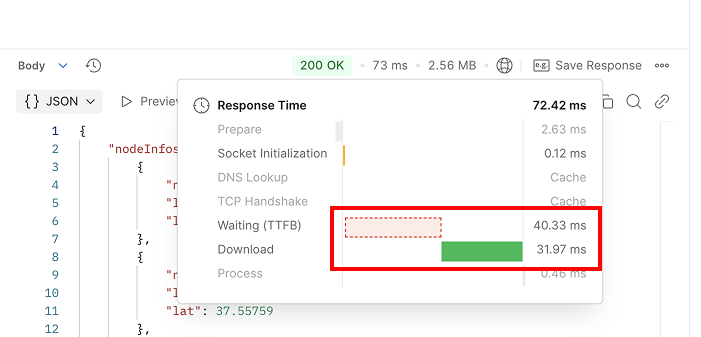
총 73ms의 응답 시간 중, 서버의 비즈니스 로직 처리에는 약 40ms가 소요되었고, Download 시간(서버의 직렬화 시간 포함)은 약 31ms가 소요되었습니다.
이 시점에서 "Download 시간은 제외해야 하는 것 아닌가?" 라는 의문이 들 수 있습니다.
정말 좋은 의문이고, 일반적으로는 제외시킬 수도 있습니다!
하지만 저희처럼 응답 데이터가 수 MB 단위에 달하는 경우, 단순히 Download 시간을 제외해버리는 것은 오히려 병목 원인을 놓칠 수 있습니다.
Postman에서는 Download 시간을 서버로부터 첫 바이트를 수신한 시점부터, 마지막 바이트를 수신할 때까지로 측정합니다.
즉, 실제 데이터가 네트워크를 통해 전달되는 데 걸린 전체 시간을 의미합니다.
그리고 중요한 점은, Spring에서는 JSON과 같은 응답을 한 번에 모두 직렬화해서 전송하는 것이 아니라, 스트리밍 방식으로 순차적으로 직렬화하며 전송한다는 점입니다.
따라서 직렬화 속도가 느릴수록 응답 전송 자체가 지연되고, 결과적으로 Download 시간에도 영향을 미칩니다.
이러한 이유로 저는 이번 분석에서 Download 시간도 하나의 유의미한 지표로 포함시키는 것이 적절하다고 판단했습니다.
5-2. Fastjson
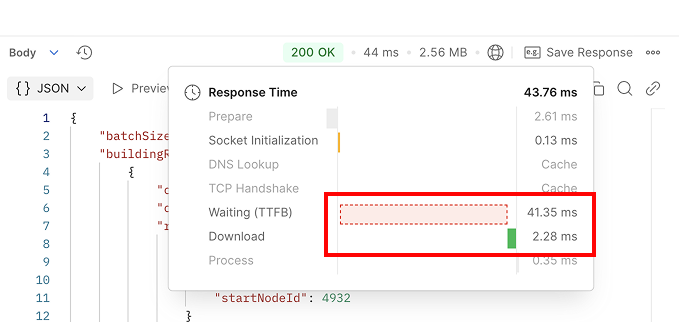
Fastjson을 사용할 경우, 총 응답 시간은 약 43ms로 측정되었고, 그 중 서버 비즈니스 로직 처리 시간은 Jackson을 사용할 때와 비슷하게 약 41ms가 소요되었습니다. 이 부분은 당연한 결과라고 볼 수 있습니다.
하지만 주목할 점은 Download 시간의 차이입니다.
기존 Jackson에서는 Download 시간이 약 31ms였던 반면, Fastjson을 사용할 경우 단 2ms로 현저히 감소한 것을 확인할 수 있었습니다.
조금 더 극단적인 상황에서 성능 차이를 보기 위해, 응답 데이터를 기존보다 약 6배 늘려 테스트를 진행해보았습니다.

그 결과, TTFB(Time To First Byte)는 두 도구 모두 유사한 수준이었지만, Download 시간에서 무려 10배 가까운 차이가 발생했습니다.
이를 통해, HTTP Response 직렬화에서도 데이터 양이 많아질수록 Fastjson이 훨씬 유리하다는 것을 간단하게나마 실험을 통해 증명할 수 있었습니다!
5-3. Fastjson 적용
적용하는 방법은 직렬화 도구만 갈아끼우면 되기 때문에 매우 간단합니다.
public class WebMvcConfig implements WebMvcConfigurer {
@Override
public void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
FastJsonHttpMessageConverter converter = new FastJsonHttpMessageConverter();
FastJsonConfig config = new FastJsonConfig();
config.setDateFormat("yyyy-MM-dd HH:mm:ss");
config.setReaderFeatures(JSONReader.Feature.FieldBased, JSONReader.Feature.SupportArrayToBean);
config.setWriterFeatures(JSONWriter.Feature.WriteMapNullValue);
// 🚨 JSONWriter.Feature.PrettyFormat 설정은 제외
converter.setFastJsonConfig(config);
converter.setDefaultCharset(StandardCharsets.UTF_8);
List<MediaType> supportedMediaTypes = new ArrayList<>();
supportedMediaTypes.add(MediaType.APPLICATION_JSON);
supportedMediaTypes.add(MediaType.TEXT_EVENT_STREAM);
converter.setSupportedMediaTypes(supportedMediaTypes);
converters.add(0, converter);
}
}
조금의 팁이라면 Feature.PrettyFormat 설정은 하지 않는 것입니다. 해당 옵션을 ON할 경우, 직렬화 객체에 "\t" 나 "\n"과 같은 문자열도 포함시킵니다.
Fastjson2 깃헙 예제에서는 보통 해당 옵션이 활성화된 예제코드가 많이 있는데요!
해당 설정은 개발자가 데이터를 보기 쉽게 정제해주는 옵션입니다.
물론 보기 좋다는 장점을 가지고 있습니다만 단점도 존재합니다.
첫번째로, 응답데이터의 용량이 약 30% 증가합니다. "\t"와 같은 문자열이 추가되기 때문에 테스트해본 결과 약 500KB 정도 차이가 나는 것을 확인했습니다.
두번째로, 클라이언트에 따라 무한 지연이 발생할 수 있습니다. 저 같은 경우 간단한 테스트는 포스트맨으로 진행했었습니다. curl 요청과는 다르게 포스트맨에서는 해당 옵션을 활성화할 경우, 응답데이터를 다 못받았다고 판단하여 무한로딩이 생기는 문제가 있었습니다.
저는 사실 응답데이터가 굳이 보기 좋게 정제할 필요는 없기 때문에 해당 옵션을 사용하지 않고 구현했습니다.
5-4. 성과
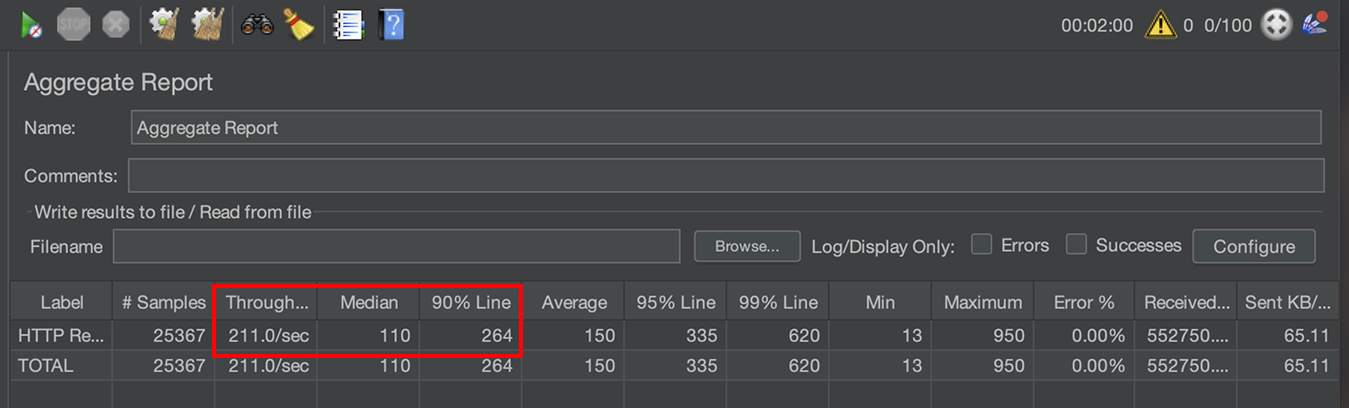
TPS : 147 -> 211 개선
P50 : 341ms -> 110ms 개선
P90 : 426ms -> 264ms 개선
TPS가 굉장히 크게 증가하였고, 전체적인 응답시간도 100%이상으로 개선하였습니다 !! 😁
6. 더이상의 개선은 현실적으로 많이 어렵다.
물론 지금까지 진행한 작업만으로도 의미 있는 개선이었지만, 여전히 저는 두 자릿수(ms) 대의 응답 시간을 목표로 삼고 있었습니다.
그래서 며칠간 다양한 가설을 세우고, 이에 기반한 개선 작업을 지속적으로 진행했습니다.
6-1. emitter 병렬 처리
SSE 통신에서 가장 큰 병목이 emitter.send() 부분이라는 점을 발견했고, 이를 병렬로 처리하면 성능이 좋아지지 않을까 하는 가설을 세웠습니다.
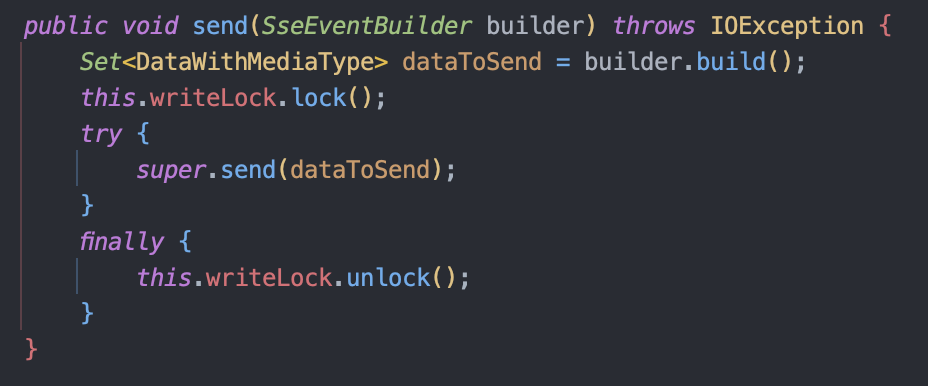
하지만 위 코드처럼 하나의 emitter에 쓰기락이 걸려 사실상 병렬로 처리하는 것이 큰 의미가 없었습니다. 너무 당연한 이야기일 수 있지만, 단일 emitter는 사실상 병렬 처리 대상이 될 수 없는 구조였습니다.
게다가, 하나의 클라이언트 요청에 대해 10개의 스레드를 생성하게 되면, vUser 100명을 기준으로 약 1,000개의 스레드가 생성됩니다.
테스트 환경의 CPU 코어 수는 고작 6개 정도였기 때문에, 이로 인해 과도한 컨텍스트 스위칭과 자원 충돌이 발생하며 오히려 성능이 저하되는 결과를 낳았습니다.
6-2. GC 타임 무시할 수 없다.
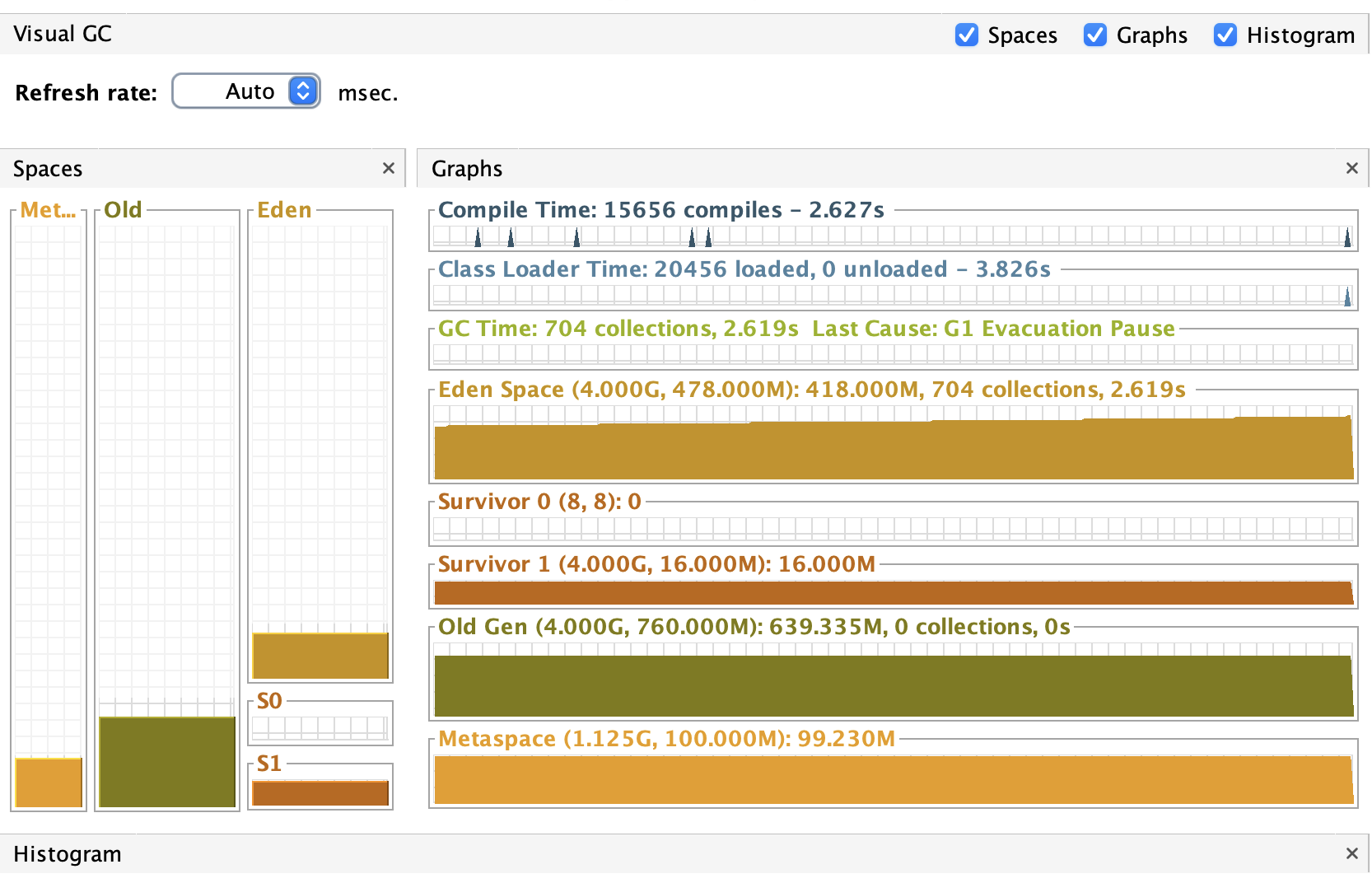
서버 사양이 상향되면서 GC는 SerialGC가 아닌 G1GC를 사용하고 있었습니다.
G1GC는 GC 타임이 줄어드는 효과는 있지만, 그렇다고 무시할 수 있는 수준은 아닙니다.
vUser가 100명인 상황에서는 짧은 시간 동안 매우 많은 객체가 생성되고 사라지게 됩니다. 이로 인해 수 ms 단위의 GC 타임조차 응답 시간에 영향을 미칠 수 있습니다.
실제로 위 측정 결과에서도 major GC는 발생하지 않았지만, minor GC만으로도 누적 2.6초의 GC 타임이 발생한 것을 확인할 수 있었습니다. 이는 응답 지연에 적지 않은 영향을 미쳤습니다.
6-3. 복잡한 계산로직 & 많은 데이터
저희 서비스는 단순히 데이터를 그대로 전달하는 것이 아니라, FE에서 렌더링하기 쉽게 BFS를 통해 구조화된 데이터를 정제하여 전달하고 있습니다.
이 과정에서 발생하는 연산 부하는 무시할 수 없으며, 현실적으로도 이 부분의 부하는 쉽게 줄이기 어렵다고 판단했습니다.
또한 응답 데이터의 크기가 수 MB 단위에 이르기 때문에 Fastjson과 같은 고성능 직렬화 도구를 사용하더라도, 데이터 양이 많아지면 직렬화 및 네트워크 전송 비용은 물리적으로 증가할 수밖에 없습니다.
6-4. 응답시간 개선은 여기까지
이러한 분석과 실험을 통해 저는 지금 단계에서의 응답 시간 개선은 한계에 도달했다고 판단했습니다.
물론 추후 인프라 변경이나 새로운 기술 도입 등을 통해 더 나은 성능을 추구할 수도 있겠지만, 그러한 작업은 훨씬 더 복합적인 분석과 검토가 필요한 영역이라 생각됩니다.
7. 마무리
이제 총 3편에 걸쳐 진행했던 응답 시간 개선 여정을 마무리하고자 합니다.
이 과정은 단순한 최적화 작업을 넘어 가설을 세우고 → 실험하고 → 원리를 파악하며 개선해 나가는 문제 해결 과정이었고, 저에게 있어 매우 값진 성장의 시간이었습니다.
물론 응답 시간 개선이라는 여정은 일단락되었지만, 여전히 고민해봐야 할 지점들은 남아 있습니다.
예를 들어:
- 로컬 캐시 운영 관점에서의 핫 키 관리 및 캐시 정책 설정
- 비동기 로깅의 운영상 문제점 등
이러한 내용은 다음 시간에 더 깊이 있게 다뤄볼 예정입니다.
긴 글 읽어주셔서 감사합니다 😄
관련 소스코드는 아래에서 확인해볼 수 있습니다!
https://github.com/softeer5th/Team2-Getit
GitHub - softeer5th/Team2-Getit: 🏆 최우수 소프티어 - 소프티어 2조 기릿팀입니다.
🏆 최우수 소프티어 - 소프티어 2조 기릿팀입니다. Contribute to softeer5th/Team2-Getit development by creating an account on GitHub.
github.com
'BE > Spring' 카테고리의 다른 글
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 2편 (4) | 2025.03.08 |
|---|---|
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 1편 (1) | 2025.03.08 |
| [Spring] 10만 요청으로 서버 장애부터, 응답시간 80% 개선까지 (1) | 2025.01.14 |
| [Spring] 빈, 컨테이너 그게 뭔데? (1) | 2023.07.18 |




댓글