
1. 시작하면서
이전 글에서는 OOM 문제를 해결하면서 메모리 사용량에 집중해봤습니다.
2025.03.08 - [BE/Spring] - [소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 1편
[소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 1편
1. 시작하면서현대자동차그룹 부트캠프 '소프티어'에서 'Uniro' 라는 프로젝트를 진행하였습니다.해당 프로젝트를 진행하면서 겪었던 대량 데이터 트러블 슈팅과 개선 과정을 적어보고자 합니다.
gamxong.tistory.com
이번 포스팅에서는 해당 로직이 핵심 로직인 만큼 부하상황에서도 빠른 응답속도를 보장하기 위한 과정들을 설명하고자 합니다.
해당 로직은 빠른 응답성이 굉장히 중요했기에 부하테스트를 진행해봤습니다.
2. 부하테스트
2-1. 사전 트래픽 조사
- 전국 지체장애인 대학생 수 : 3725명
- 트래픽 예상
- 3725명중 10% + 각 학교의 관계자 총합 50명 예상 -> 예상 트래픽 400명
- 사용 패턴 예측 : 5회 미만(지도 서비스 특성 및 프론트 캐싱 고려)
실제 전국 대학생분들이 사용하더라도 원활한 서비스를 목표로 했기 때문에 이러한 데이터를 바탕으로 진행했습니다.
2-2. 부하테스트 계획
부하량
- vUser : 50
- Ramp-up : 5
- Duration : 120s
부하테스트를 진행할 때 핵심은 동시 접속자라고 생각합니다. 따라서 400명 전체가 동시에 접속할 가능성은 낮고, 일반적으로 실사용자의 약 5~10% 정도가 동시에 접속하는 것으로 추정했습니다.
따라서 5~10% 기준으로 동시 접속자 수는 20명 ~ 40명, 이를 감안하여 여유 있는 부하를 보기 위해 vUser 50명으로 설정하였습니다.
성능 지표 - TPS, p50, p90
성능 지표로서는 TPS, p50, p90 지표를 사용하고자 했습니다. 각 지표를 사용한 이유에 대해 말씀드려보겠습니다.
1. TPS
- 초당 얼마나 많은 요청을 처리할 수 있는지를 나타내는 지표
- 전체 시스템의 처리 능력(Capacity)을 확인하고자 함.
2. p50
- 전체 요청 중 50%가 이 시간 이하로 응답됨을 나타내는 지표
- 부하 상황에서 대부분의 사용자가 경험하는 평균적 성능 수준을 객관적으로 파악하고자 함.
3. p90
- 전체 요청 중 90%는 이 시간 이내에 응답, 나머지 10%는 더 오래 걸림을 나타내는 지표
- 부하 상황에서 대부분의 사용자들이 어느 정도까지의 느린 응답을 경험하는지를 파악하고자 함.
2-3. 부하테스트 결과
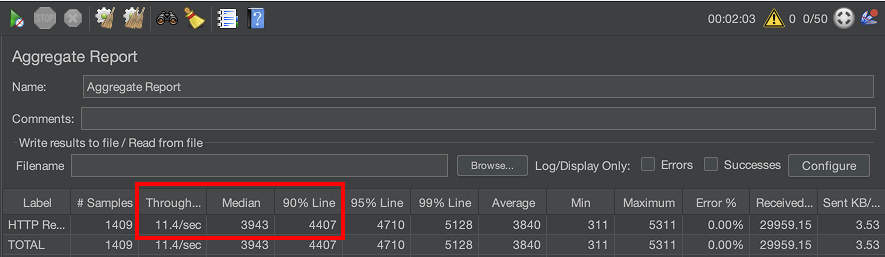
(위 이미지에서 보이는 2개의 row는 아예 동일한 값입니다. 앞으로 나오는 이미지에서도 2개의 row는 아예 동일한 값입니다.)
TPS 11 밖에 되지 않고, p50 응답시간도 약 4s 정도로 굉장히 느린 것을 확인할 수 있습니다.
2-4. 목표 설정
1. TPS : 50 이상
2. P50, P90 : 300ms 내외
동시 접속자 50명이 순간적으로 요청을 보내는 상황에서도, 시스템이 병목 없이 요청을 처리할 수 있어야 합니다. TPS 50 이상이면 이러한 순간적인 피크 트래픽도 감당 가능하다는 의미이기에 이렇게 설정했습니다.
대부분의 요청이 300ms 이내에 처리되면, 사용자 입장에서 ‘빠르다’고 느낀다고 생각했습니다.
특히 지도 서비스의 경우 지연 응답이 체감 성능에 직접적인 영향을 미치므로, 빠른 응답 유지가 중요합니다.
이에 사용자가 불편함을 느끼지 않는 응답 속도 300ms를 목표로 개선 작업을 진행했습니다.
3. Redis를 활용한 조회속도 개선
일단 빠른 조회속도를 보장해주는 캐시가 필요했기 때문에 S3와 같은 디스크 기반의 서비스는 선택지에서 탈락되었습니다.
캐시로서 많이 사용하는 로컬캐시와 Redis 중에 선택하고자 했습니다.
그 중, 로컬캐시는 빠른 응답을 위해 가장 좋은 선택지 였습니다.
하지만 앞 선 1편 내용과 같이 현재 서버의 메모리 사용량이 굉장히 높은 상황이었습니다. 로컬캐시를 사용하면 그에 따라 메모리 사용량이 매우 높아질 것이 예상되었습니다.
또한, 저희는 기술 선택 당시 발표에서 챌린징 요소로서 오토스케일링까지도 고려하고 있었습니다.
그래서 안정성 & 확정성을 고려하여 서버와 독립된 환경을 구축할 수 있는 Redis를 도입했습니다.
Redis를 사용하지 않고, 더 좋은 성능의 인스턴스를 만들어 로컬캐시를 사용하는 것도 고민했습니다.
하지만 현재는 무료 인스턴스 2개(Spring 서버, Redis 서버)를 사용하지만, 하나로 합치면 비용이 발생하기에 이 방식은 제외가 되었습니다.
그래서 Redis와 같은 글로벌캐시를 활용하여 메모리 사용량을 줄여보고자 했습니다.
3-1. Redis에 많은 데이터 저장은 항상 조심해야 한다.
Redis에 데이터를 저장하는 로직을 구현할 때, 예전에 봤던 우아한 Redis 가 생각났습니다.
Redis는 기본적으로 싱글스레드 인메모리 DB 입니다.
다시 말해, 1번에 1개의 명령어만 실행할 수 있습니다.
그러므로 한 서비스에서 요청된 명령어에 대한 작업이 끝나기 전까진 다른 서비스에서 요청하는 명령을 못 받아들이는 구조입니다.
따라서 Redis를 운영하면서 조심해야 하는 것이 keys 와 같은 "O(N) 명령어", "하나의 키에 많은 컬렉션이 저장되는 것"입니다.
keys 와 같은 명령어를 불가피하게 사용해야 된다면, SCAN 방식을 사용을 권장합니다.
저희 서비스는 이전 포스팅에서도 언급한 것과 같이 하나의 대학교에 최대 5만건의 데이터가 저장되어 있습니다.
따라서 콘보이 현상으로 인해 서비스가 느려질 가능성이 높았습니다.
이를 보완하고자 우아한 Redis를 발표하신 강대명님 말씀처럼 batch 단위로 나눠서 저장하는 방식을 채택하였습니다.
운이 좋게도, 이미 이전 포스팅에서 batch 단위로 동작하고 있었기 때문에 해당 로직에서 redis에 데이터를 저장하는 로직도 어렵지 않게 추가할 수 있었습니다.
private void saveAndSendBatchByStream(String redisKeyPrefix, int batchNumber, ...) {
LightRoutes value = new LightRoutes(batch);
// redis 에 batch 단위로 저장하는 로직
redisService.saveData(redisKeyPrefix + batchNumber, value);
processBatchByStream(batch, nodeInfos, coreRoutes, buildingRoutes);
batch.clear();
}
"{univId}:batch:{batchNumber}" 와 같은 패턴으로 key 값을 구성하여 2500개 단위로 분할해서 저장하였습니다.
3-2. 성과

TPS : 11 -> 23 개선
P50 : 3943ms -> 1762ms 개선
P90 : 4407ms -> 2091ms 개선
전체적인 성능지표가 나름 100% 개선되었습니다!!
하지만 아직 저희가 목표했던 TPS 50이나 응답속도 300ms에는 도달하지 못했습니다.
어떤 것이 문제였을까요?
4. 데이터가 많아지면 역직렬화 시간도 무시할 수 없다.
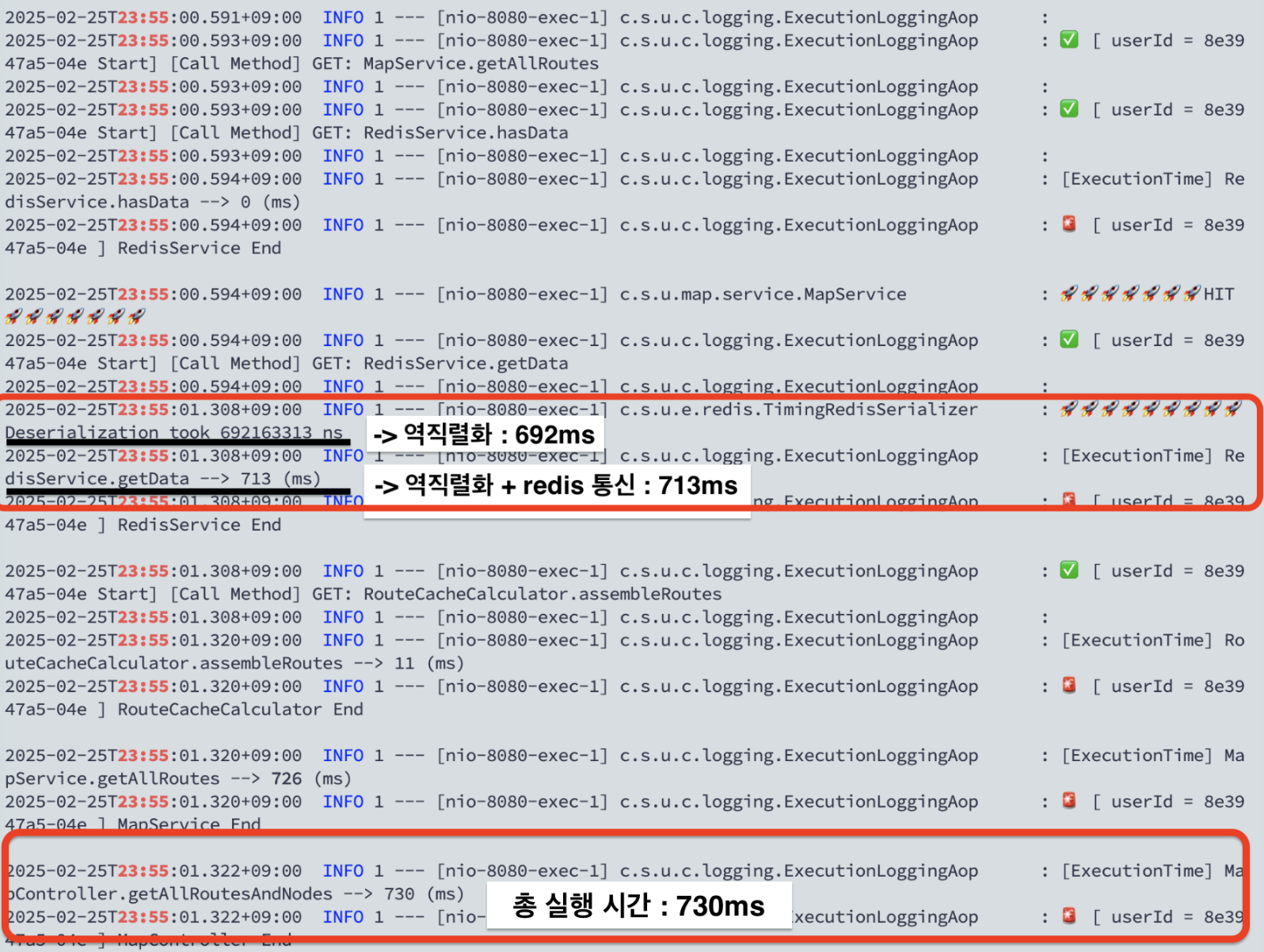
저는 실행시간을 면밀히 분석해봤습니다.
그리고 굉장히 특이한 부분을 확인할 수 있었습니다.

특정 요청의 실행시간을 그래프로 도식화한 것입니다.
총 실행시간 730ms 중 redis 관련된 로직에서 97% 이상이 소요됐습니다.
그리고 더 자세히 분석해본 결과, 네트워크 시간은 얼마 안되고 역직렬화 하는데만 692ms가 걸렸습니다.
왜 이런 문제가 발생하는지 파악하기 위해 Spring에서 기본적으로 사용되는 Jackson 라이브러리를 알아봤습니다.
4-1. 기존 Jackson 직렬화 방식
기존에는 Jackson을 사용하여 객체를 JSON으로 변환하고 Redis에 저장했습니다. 그러나 다음과 같은 한계가 있었습니다.
- 리플렉션 기반 처리
- Jackson은 기본적으로 객체를 JSON으로 직렬화할 때 오버헤드가 큰 Reflection을 사용해 필드에 접근하여 처리
- 기본적으로 많은 동적 처리를 감수하고 유연성을 취한 라이브러리
- SISD (Single Instruction, Single Data) 원리
- 한번에 하나의 명령어가 하나의 데이터에만 작용함
정리하자면, 데이터가 많지 않을 경우 Jackson 방식이 괜찮은 선택이 될 수 있습니다.
하지만 저희와 같이 데이터가 N만건 정도 될 경우에는 Jackson 방식은 한계가 있다고 할 수 있습니다. 저는 그래서 이보다 더 좋은 성능을 내는 직렬화 도구를 물색해봤습니다.
4-2. Fastjson 사용
https://github.com/alibaba/fastjson2
GitHub - alibaba/fastjson2: 🚄 FASTJSON2 is a Java JSON library with excellent performance.
🚄 FASTJSON2 is a Java JSON library with excellent performance. - alibaba/fastjson2
github.com
Fastjson은 Alibaba에서 개발한 고속 JSON 직렬화 라이브러리로, 최소한의 메모리 오버헤드와 빠른 처리 속도를 목표로 설계되었습니다. 특히, JSON 변환 과정에서 불필요한 객체 생성이나 Reflection 사용을 줄이고 최적화된 알고리즘을 적용하여, 많은 데이터가 오고가는 과정에서의 오버헤드를 줄여줍니다.
실제 직렬화 도구들의 벤치마킹 결과를 보면 압도적인 성능을 확인할 수 있습니다.

최근에는 기존 Fastjson에서 버전 업이 된 Fastjson2가 릴리즈 되었습니다. 훨씬 더 좋은 성능으로 출시되었기 때문에 해당 버전을 기준으로 설명으로 이어나가겠습니다.
Jackson보다 Fastjson이 빠른 이유
Fastjson이 Jackson보다 빠른 이유는 "리플렉션 vs ASM", "SISD vs SIMD" 총 2가지 측면에서 비교할 수 있습니다.
Fastjson2는 Java의 Vector API를 적극 활용하여 병렬 처리, 즉 SIMD(Single Instruction Multiple Data) 방식으로 데이터를 처리합니다.
Fastjson2는 데이터를 직렬화하거나 역직렬화할 때, 단순히 하나씩 순차 처리하는 대신 Vector API를 통해 한 번의 명령어로 여러 데이터 요소를 동시에 계산합니다. 이 방식은 CPU의 SIMD 명령어 집합을 활용하여 64비트 연산을 병렬로 수행하게 해, 각 데이터 요소마다 처리 시간을 대폭 단축시킵니다.
또한, Fastjson2는 성능을 위해 Java의 ASM 라이브러리를 활용해, 런타임 시 객체 접근 코드를 바이트코드 수준에서 생성합니다.
즉, 컴파일 시점처럼 동작하는 정적 코드 경로를 만들어 내어 직접 메모리에 빠르게 접근이 가능하며, 메서드 인라이닝 등 JVM 최적화에 유리합니다.
반면 Jackson은 리플렉션 기반의 SISD 처리 방식으로 인해 각 필드 접근 시마다 메서드 호출과 타입 검증 등의 오버헤드가 발생하고, 메모리 접근이 불규칙해 CPU 캐시 효율이 떨어집니다. 이로 인해 루프 내 연산이 많은 경우 성능 병목이 발생하기 쉬우며, 메서드 인라이닝과 같은 JIT 최적화 기회도 제한적입니다.
결국, Jackson은 유연성과 안정성 측면에서는 강점을 가지지만, 성능을 극대화해야 하는 환경에서는 구조적인 한계가 있습니다.
이에 반해 Fastjson2는 속도와 CPU 친화성 측면에서 현저한 이점을 제공하며, 성능 중심의 선택이 필요한 상황에서는 더욱 적합한 대안이 됩니다.
그래서 저희는 Fastjson2 라이브러리를 선택하게 되었습니다.
(번외) SISD vs SIMD
번외로, 앞선 SIMD의 병렬처리 설명이 와닿지 않을 수도 있을 것 같아 구체적인 코드 예시를 보여드리겠습니다!
[배열의 각 원소에 2를 곱하는 연산]을 한다고 가정해보겠습니다.
1. SISD (jackson 방식)
int[] input = {1, 2, 3, 4, 5, 6, 7, 8};
int[] output = new int[input.length];
for (int i = 0; i < input.length; i++) {
output[i] = input[i] * 2;
}
2. SIMD (Fastjson 방식)
int[] input = {1, 2, 3, 4, 5, 6, 7, 8};
int[] output = new int[input.length];
VectorSpecies<Integer> SPECIES = IntVector.SPECIES_PREFERRED;
int i = 0;
for (; i < SPECIES.loopBound(input.length); i += SPECIES.length()) {
IntVector vector = IntVector.fromArray(SPECIES, input, i);
IntVector result = vector.mul(2); // SIMD로 한 번에 곱하기
result.intoArray(output, i);
}
SISD 방식은 for문을 8번 도는 반면에, SIMD 방식은 SPECIES_PREFERRED 의 길이(보통 8) 단위로 for문을 돌기에 1번만에 연산이 가능합니다.
구현코드
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 키는 String, 값은 FastJson으로 변환된 JSON 문자열 저장
StringRedisSerializer serializer = new StringRedisSerializer();
FastJsonRedisSerializer<LightRoutes> fastJsonRedisSerializer = new FastJsonRedisSerializer<>(LightRoutes.class);
template.setKeySerializer(serializer);
template.setValueSerializer(fastJsonRedisSerializer);
return template;
}
4-4. 성과
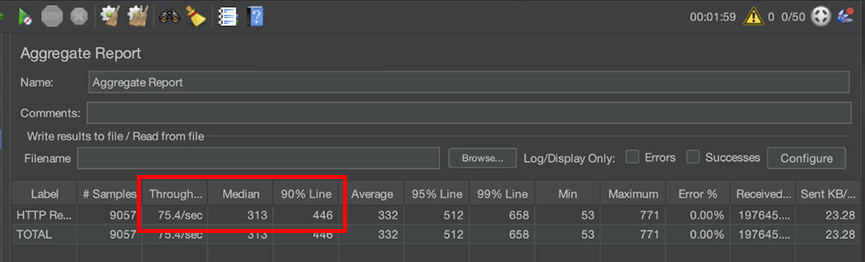
TPS : 23 -> 75 개선
P50 : 1762ms -> 313ms 개선
P90 : 2091ms -> 446ms 개선
p90 수치가 조금 아쉽지만, 이 방식을 통해 저희가 목표했던 TPS 50 이상과 300ms 내외의 응답시간을 달성할 수 있었습니다!!
이로써, 저희가 목표했던 성능개선을 달성할 수 있었습니다 😃
4-5. Fastjson의 Tradeoff
모든 기술의 도입에는 항상 장점만 있을 수 없습니다. Fastjson을 사용하면서 어떤 단점이 생기는지 궁금했습니다.
1. 보안 이슈
가장 큰 문제는 불안정한 라이브러리라는 것입니다. 가장 유명했던 이슈로 RCE(Remote Code Execution) 이슈가 있었습니다. AutoType 기능으로 인해 다수의 RCE 취약점을 노출한 바가 있습니다. 이 사건으로 많은 개발자가 해당 라이브러리에 대한 신뢰를 잃었다고 합니다..
2. Java Vector API의 플랫폼 의존성
Java Vector API는 아직 상대적으로 새로운 기술이며, JDK 23 기준으로 아직 인큐베이터 단계의 기능입니다. 그래서 아직 안정적인 기능이라고 보기엔 어렵습니다.
실제로 SIMD 명령어는 CPU 아키텍처에 따라 다르기 때문에, JVM이 내부적으로 어떤 SIMD 명령어로 번역하느냐에 따라 성능이 좌우될 수 있습니다. 물론 이 문제를 해결하기 위해 노력하고 있지만 아직 JDK 23에서는 해결되지 않았습니다. 실제 문서를 보면 아래와 같은 내용이 있습니다.
There is a risk that the API will be biased to the SIMD functionality supported on x64 architectures, but this is mitigated with support for AArch64. This applies mainly to the explicitly fixed set of supported shapes, which bias against coding algorithms in a shape-generic fashion. We consider the majority of other operations of the Vector API to bias toward portable algorithms. To mitigate that risk we will take other architectures into account, specifically the ARM Scalar Vector Extension architecture whose programming model adjusts dynamically to the singular fixed shape supported by the hardware. We welcome and encourage OpenJDK contributors working on the ARM-specific areas of HotSpot to participate in this effort.
한 마디로 아래와 같습니다.
Intel CPU(x64)에는 잘 맞는데 ARM(AArch64)에선 덜 최적화될 수도 있어요.
그래서 해결해보는 중이에요.
다시 말해, JVM 구현, JDK 버전, 하드웨어 플랫폼에 따라 성능이 일관되지 않을 수 있다는 것입니다.
그럼에도 불구하고, 이러한 단점을 상쇄시킬 정도로 큰 성능개선을 이뤘기 때문에 저희는 해당 도구를 그대로 유지하고자 했습니다.
5. GC 튜닝을 통한 응답속도 개선?!
5-1. 응답시간이 튀는 문제

데모데이 시연을 대비해 장시간의 지속적인 부하 테스트를 수행하던 중, 응답 시간 그래프에서 간헐적으로 응답 시간이 급격히 증가하는 지점을 발견했습니다.
해당 시점의 메트릭을 Grafana에서 분석한 결과, Major GC 발생에 따른 Stop-the-World(STW) 이벤트가 수 초 단위로 발생하고 있었고, 이로 인해 애플리케이션 응답이 지연되고 있었음을 확인했습니다.
Java 17부터 기본 GC가 G1GC로 설정되어 있어, 일반적으로는 수 밀리초(ms) 단위의 짧은 GC 지연만 발생한다고 알고 있었기에 다소 예상 밖의 결과였습니다. 그래서 더욱 원인을 깊이 파고들었습니다.
5-2. Java 17에서 기본 GC가 SerialGC였던 이유

조사 결과, Java 17을 사용하더라도 JVM은 CPU 코어 수와 시스템 스펙에 따라 GC 방식을 자동 결정하며, 1~2개의 vCPU를 가진 저사양 환경에서는 G1GC 대신 SerialGC를 기본으로 선택한다는 것을 알게 되었습니다.
제가 사용한 EC2 t2.micro 인스턴스는 vCPU 1개, RAM 1GB로 구성되어 있어, 성능 측면에서 SerialGC가 적절한 선택이었던 셈입니다.
SerialGC는 싱글 스레드 기반으로 동작하며, G1GC보다 메모리 오버헤드가 적기 때문에 저사양 환경에서는 오히려 더 유리할 수 있습니다.
이는 JVM이 단순히 JDK 버전에 따라 GC를 고정하는 것이 아니라, 실행 환경에 맞춰 최적의 GC 전략을 선택하도록 설계되어 있다는 점에서 매우 흥미로웠던 부분이었습니다.
JVM이 어떤 GC를 사용 중인지 확인하는 방법:
java -XX:+PrintCommandLineFlags -version 명령어를 사용하면, JVM이 어떤 옵션으로 구동되고 있는지 확인할 수 있습니다.
따라서 저희는 G1GC로 강제로 변경하지 않고 다른 방법을 찾아봤습니다.
5-3. New 영역을 조절하여 GC 튜닝하기
G1GC로의 전환이 어려운 상황에서, 현재 리소스 환경 내에서 해결책을 찾아야 했습니다.
초기 JVM 설정은 다음과 같았습니다:
-Xmx500m
최대 힙 사이즈만 설정된 상태였고, 초기 힙 사이즈(-Xms)는 명시되지 않았기 때문에 JVM은 실행 중 점진적으로 힙을 확장하게 됩니다. 이로 인해 Eden 영역이 작게 잡히고, GC가 자주 발생하며, 객체들이 빠르게 Old 영역으로 밀려 Full GC가 빈번히 발생하는 구조였습니다.
이를 아래와 같이 개선했습니다:
-Xmx500m -Xms500m
초기 힙 크기와 최대 힙 크기를 동일하게 설정함으로써, JVM이 시작 시점부터 전체 힙을 할당받아 안정적인 메모리 분배가 가능하도록 만들었습니다.
참고: NAVER D2의 GC 튜닝 가이드에서는 GC 튜닝의 첫 단계로 반드시 -Xms, -Xmx 옵션을 명확하게 지정하라고 강조하고 있습니다.
5-4. 트래픽 기준으로 Eden 영역 검증
현재 서비스의 평균 메모리 사용량은 약 300KB이며, 동시 접속자 수는 100명 수준이었습니다. 이를 기준으로 계산하면,
- 전체 Eden Space : 128MB
- 배치 단위의 평균 메모리 사용량 : 300KB
- 여유롭게 동시접속 100인 경우 : 300KB * 100 = 30.0MB
Eden 영역을 128MB로 확보한다면, 이 정도의 트래픽은 충분히 감당 가능한 수준이었습니다. 즉, 적절한 메모리 초기화와 Eden 공간 확보만으로도 Full GC 빈도는 획기적으로 줄어들고, 응답 속도 안정성도 확보할 수 있었습니다.
5-5. 성과
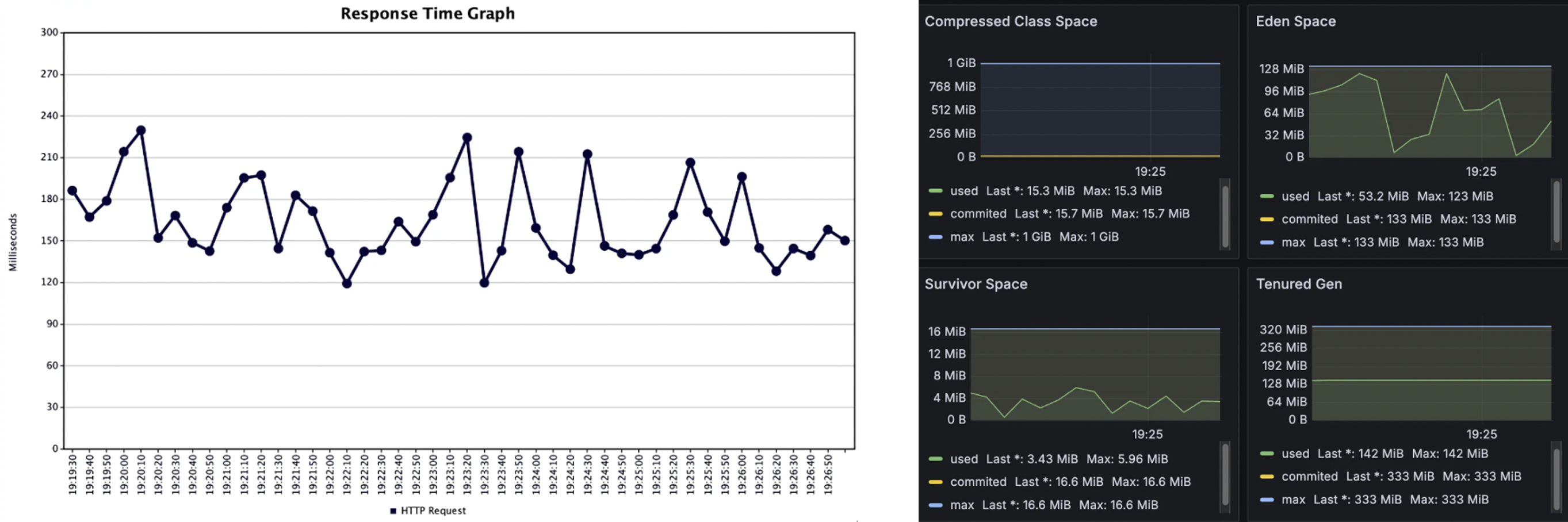
응답시간 그래프가 이제 일정해진 것을 확인할 수 있습니다.
또한, Old 영역으로 객체가 넘어가는 현상도 막을 수 있었습니다.
이런 식으로도 접근해볼 수 있다!
하지만 중요한 점은, 이런 설정들이 절대적인 정답이 아니라는 점입니다.
각 서비스의 특성과 트래픽 패턴, 실행 환경(CPU, Memory 등)에 따라 GC의 동작 방식은 천차만별이기 때문입니다.
저희 서비스만 하더라도 트래픽이 더 많아질 경우, 해당 설정은 더이상 유효하지 않을 것입니다. 또한, 실제 서비스환경에서는 동적 힙 설정이 훨씬 더 좋은 옵션이 될 수도 있습니다.
제가 이번 절에서 얘기하고자 하는 내용은 "이런 식으로도 접근해볼 수 있다." 정도로 이해해주시면 좋을 것 같습니다.
따라서 설정을 적용했다면 반드시 지속적으로 GC 로그나 메트릭을 모니터링하며 효과를 확인하고, 필요 시 조정해야 합니다.
GC 튜닝은 단발성 작업이 아닌 데이터 기반의 반복적인 최적화 과정입니다. 여러분의 서비스 환경에 맞는 설정을 탐색해 나가시길 바랍니다!
6. 결론 & 다음편 예고
이전에는 어떤 기술을 적용할 때, 단순히 "적용했다"는 데에 만족하고 그 기술이 최선의 선택이었는지, 더 나은 방향이 있었는지에 대해 깊이 고민하지 못했던 것 같습니다.
하지만 이번 소프티어 부트캠프에서는 팀원들과 함께 끈질기게 토론하고, 기술 선택의 이유와 대안을 끝까지 물고 늘어진 덕분에, 목표했던 성능 개선을 실제로 이루어낼 수 있었습니다.
특히 이번 경험을 통해 확증 편향된 사고를 경계하는 태도의 중요함을 다시 한 번 느꼈습니다.
처음엔 확신했던 기술적 선택이었지만, 팀원의 비판적 시각을 열린 마음으로 받아들이지 않았더라면 이렇게 날카로운 솔루션으로 이어지기는 어려웠을 것입니다.
앞으로도 저는 비판을 수용하고 끈질기게 파고드는 개발자로 성장하고 싶다는 생각이 들었습니다!
그리고 사실, 여기서 이야기가 끝난 건 아닙니다.
이후에 부트캠프가 종료되고 무료 서버 이용도 끝나면서 또 다른 변화가 생겼습니다.
덕분에 더 좋은 성능의 서버로 이전할 수 있었고, 그 과정에서 새로운 인프라 환경에서의 성능 튜닝과 아키텍처 고민을 해볼 수 있는 기회가 생겼습니다.
다음 포스팅에서는 이 서버 이관 과정에서 어떤 개선을 했는지, 그리고 기존 설계의 한계를 어떻게 극복했는지를 공유드릴 예정입니다.
많은 기대 부탁드립니다! 😊
'BE > Spring' 카테고리의 다른 글
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 3편 (5) | 2025.03.25 |
|---|---|
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 1편 (1) | 2025.03.08 |
| [Spring] 10만 요청으로 서버 장애부터, 응답시간 80% 개선까지 (1) | 2025.01.14 |
| [Spring] 빈, 컨테이너 그게 뭔데? (1) | 2023.07.18 |




댓글