
1. 시작하면서
현대자동차그룹 부트캠프 '소프티어'에서 'Uniro' 라는 프로젝트를 진행하였습니다.
해당 프로젝트를 진행하면서 겪었던 대량 데이터 트러블 슈팅과 개선 과정을 적어보고자 합니다.
2. 서비스 소개
일단 문제상황을 이해하기 위해선 어떻게 구현되었는지 짚고 넘어갈 필요가 있습니다.
최대한~~ 아주 쉽게 설명해보겠습니다~!
2-1. 지도 서비스인데 외부 API 를 사용하지 않는다?
먼저 저희 서비스는 네이버 API와 같은 외부 API를 사용하는 것이 아닌, 저희가 자체적으로 길에 대한 데이터를 저장하고 있습니다.
(이 부분이 어떻게 보면, 일반 서비스와 큰 차이점이며 저희도 해당 부분이 가장 챌린징 요소였습니다.)
그렇게 구현할 수 밖에 없었던 이유는 기존의 길찾기와 다르게 장애인분들 위한 저희만의 길찾기 서비스를 제공하기 위해서입니다.
이를 위해 DB에는 노드와 간선들을 모두 저장하고 있었습니다.

위 사진을 보면, 파란색 길이 모두 저희가 가지고 있는 데이터입니다.
당연히 저희는 1~2달 정도의 프로젝트이기 때문에 전국의 모든 길 데이터를 얻는 건 현실적으로 불가능했습니다.
또한, 프로젝트 주제가 "대학생들의 통학의 어려움을 해결"이었기 때문에 저희는 서비스를 대학 캠퍼스 내부로 한정했습니다.
2-2. 5만건 데이터는 어디서 온건가?

그렇다면 포스팅의 제목이었던 5만건의 데이터는 대체 어디서 나온 숫자일까요?
위 사진을 보시면, 곡선 표현이 나름 자연스럽게 되어있는 것을 확인할 수 있습니다.
네 맞습니다. 저희는 모든 길을 3m 단위로 잘라 저장하고 있었습니다.
(사실 곡선표현의 이유 외에도 '길 추가 기능'을 위해서도 작은 단위로 자르고 있지만 이 부분은 생략하도록 하겠습니다.)
저희 FE 팀에서 만들어준 어드민 툴을 활용하여 전국에서 가장 큰 서울대 길을 찍어보면 아래와 같은 결과가 나옵니다.
FE 팀에서 만들어준 GOAT 어드민 툴 덕분에 서울대 길 데이터도 10~20분이면 생성 가능합니다 ㅎㅎ

제대로 못찍은 데이터와 '추가된 길'까지 합치면 현재 아래와 같습니다.
- Node : 약 12500개
- Route(간선) : 약 12500개
여기에 저희는 버전 정보를 조회하는 기능도 있기 때문에 x2가 되어 총 5만건 정도가 됩니다.
전국 단위로 확장하면, 서울대는 5만건 정도이지만 평균 대학 크기로 하면 1만건 정도 됩니다.
전국에 대학교 약 300개 정도 되기 때문에 1만건 * 300 = 300만건 정도의 데이터가 됩니다.
하지만 저희 서비스는 대학교 기반 서비스이기에 서울대 기준으로 계속 설명을 드리겠습니다.
3. 문제 발생 - OOM
저희 서버는 EC2.micro 를 사용하고 있었습니다.
다시 말해, 메모리 1GB 와 vCPU 2개인 어떻게 보면 굉장히 열악한(?) 서버를 사용한다는 것입니다.
하나의 인스턴스 내에서 여러 서비스를 컨테이너로 띄워 사용하다보니 spring 컨테이너에게 할당해줄 수 있는 힙 메모리는 500MB 정도밖에 되지 않았습니다.
그리고 테스트를 진행하다 데모데이 상황을 고려하여 동시에 15건의 요청을 해봤습니다.

OOM 발생...!
4. 원인 분석
OOM 문제가 발생하고, BE 팀원과 함께 바로 원인 분석에 들어갔습니다.
어떤 특정한 코드가 잘못돼서 생긴 문제가 아닐까 생각해서 heapdump 파일을 추출해서 분석해봤습니다.
분석해봤을 때, List 객체에서 생긴 문제였습니다.
해당 서비스는 정식 출시를 목표로 하지 않았기에 모니터링 툴을 따로 구축하지 않았습니다.
하지만 정확한 디버깅을 위해 프로메테우스 모니터링 서버를 구축하여 메모리 사용량을 관찰해봤습니다.
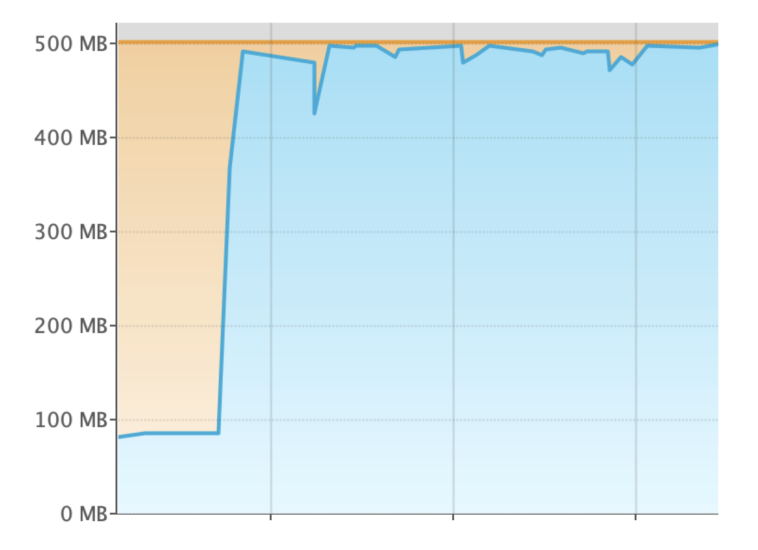
분석 결과, '모든 길 조회 로직'에서 각각의 요청이 약 15MB의 과도한 메모리를 소비하고 있어 OOM 문제가 발생했습니다.
다시말해, 위에서 언급한 5만건의 데이터 조회 == 약 15MB 메모리 소비 라는 것입니다.
따라서 15건의 동시요청을 하게 된다면,
- 15건 * 15MB = 225MB 를 사용
- 기본적인 힙 사용량 약 200MB
- 프론트 측에서 추가적인 다른 요청들
이 정도의 메모리를 사용하게 되어 모두 합쳐지면 500MB가 훌쩍 넘는 수치가 됩니다.
4-1. 사용자가 보고 있는 영역만 조회해서 줄까?
이 문제를 해결하기 위해 구현방식을 바꿔 데이터 자체를 다이어트 시켜보고자 했습니다.
하지만 저희는 전국데이터가 아닌 한 화면에 다 들어오는 캠퍼스 내로 한정했기 때문에 사용자가 보고있는 영역만 조회해서 주는 것이 큰 효과가 없었습니다.
4-2. LOD (Level Of Detail) 방식을 차용해볼까?
팀원이 제안했던 의견 중, 게임에서 많이 사용하는 LOD 를 이용해볼까도 고민했습니다.
최대 Zoom-in 를 했을 때는 모든 길을 다 보여주고, 최대 Zoom-out 를 했을 때는 군데군데 보여줘 적당한 곡선표현이 가능하게 말입니다.
이 방식은 상당히 괜찮은 방법이었습니다.
하지만 구현이 복잡하였고, 엣지 케이스가 너무 많다는 생각이 들었습니다.
또한, 성능을 위해 프론트 측에서도 저희가 준 길 정보를 캐싱하여 여러 비즈니스 로직에 활용하고 있었는데요!
만약 해당 방식을 하게 될 경우 굉장히 많은 로직의 수정이 필요했습니다.
그때 당시에는 시간도 많이 촉박했기 때문에 해당 방식을 도입하긴 어려웠습니다.
하지만 정말 좋은 방법이라고 생각해서, 나중에 이런 식으로 풀어내도 재밌을 것 같습니다!
4-3. 서버 최대 메모리 사용량을 줄여보자.
저희 BE 팀은 프론트에서의 최소한의 수정으로 이 문제를 해결하고자 했습니다.
그리고 다음과 같은 생각을 했습니다.
서버에서 불러오는 데이터 자체를 줄여보면 어떨까?
결국 OOM 문제가 발생하는 이유는 최대 메모리 사용량을 초과했기 때문입니다. 그래서 데이터 자체를 줄여 메모리 사용량을 줄여보고자 했습니다.
그리고 초기에 저희가 생각했던 방식은 '1. 프로젝션 방식' 과 '2. Stream 방식' 입니다.
간단한 프로토타입을 통해 PoC 과정을 거친 후, 바로 작업에 들어갔습니다.
5. 문제 해결
5-1. 프로젝션
일단 가장 쉽게 떠오른 방식은 필요한 필드 데이터만 조회하는 프로젝션 입니다.
앞서 언급한 노드 데이터와 간선 데이터에는 여러 정보가 저장되어 있습니다.
하지만 실제 길을 조회할 때는 전체의 30~40% 데이터만 사용됐습니다.
그래서 전체 필드를 모두 조회하는 것이 아닌, 필요한 필드만 프로젝션하여 개선해보고자 했습니다.
AS-IS
@EntityGraph(attributePaths = {"node1", "node2"})
@Query("SELECT r FROM Route r WHERE r.univId = :univId")
List<Route> findAllRouteByUnivIdWithNodes(Long univId);
TO-BE
@Query("""
SELECT new com.softeer5.uniro_backend.map.service.vo.LightRoute(r.id, r.distance, n1, n2)
FROM Route r
JOIN r.node1 n1
JOIN r.node2 n2
WHERE r.univId = :univId
""")
List<LightRoute> findAllLightRoutesByUnivId(Long univId);
이런식으로 LightRoute, LightNode 라는 객체를 만들어 필요한 데이터만 프로젝션 하였습니다.
15MB -> 8MB (5만건 데이터 : 4MB + 비즈니스 로직 및 DTO : 4MB)
이 방식을 통해 하나의 요청당 메모리 사용량이 15MB 에서 8MB 정도까지 감소할 수 있었습니다.
그 결과, 30명 정도의 동시요청까지도 OOM이 발생하지 않게 되었습니다.
5-2. Stream 방식
앞선 개선을 통해 30명 정도까지는 버틸 수 있었지만, 그 이상의 요청이 들어오면 여전히 OOM 문제가 발생했습니다.
이 문제의 원인을 생각했을 때, 한 번에 너무 많은 데이터를 메모리에 로드하고 있다고 생각했습니다.
기존 방식에서는 데이터베이스에서 조회된 5만 건의 데이터를 한꺼번에 메모리에 적재했기 때문입니다.
이를 해결하기 위해 도입한 방식이 Stream 처리입니다.
사실 Stream과 유사한 방식으로 Chunk 단위로 조회하는 방법도 있습니다.
Chunk 단위 조회는 한 번에 Chunk 단위를 모두 메모리에 적재해야 했기 때문에 Stream에 비해 메모리 부담이 크다고 생각했습니다.
Stream 방식이란?
Stream 방식은 데이터베이스에서 대량의 데이터를 조회할 때, 전체 데이터를 한 번에 메모리에 적재하는 것이 아니라 커서를 이용해 한 건씩 순차적으로 가져오는 방식입니다.
즉, 기존 방식처럼 한 번에 5만 건을 조회하여 메모리에 올리는 것이 아니라, 데이터를 하나씩 가져오면서 특정 개수(예: 1,000건)가 쌓이면 해당 Batch 단위로 처리한 후 메모리에서 해제하는 방식으로 동작합니다.
이를 통해 메모리 사용량을 최소화하고, 대량 데이터 처리 시에도 OOM(Out of Memory) 문제가 발생하지 않도록 개선할 수 있습니다.
기존 방식
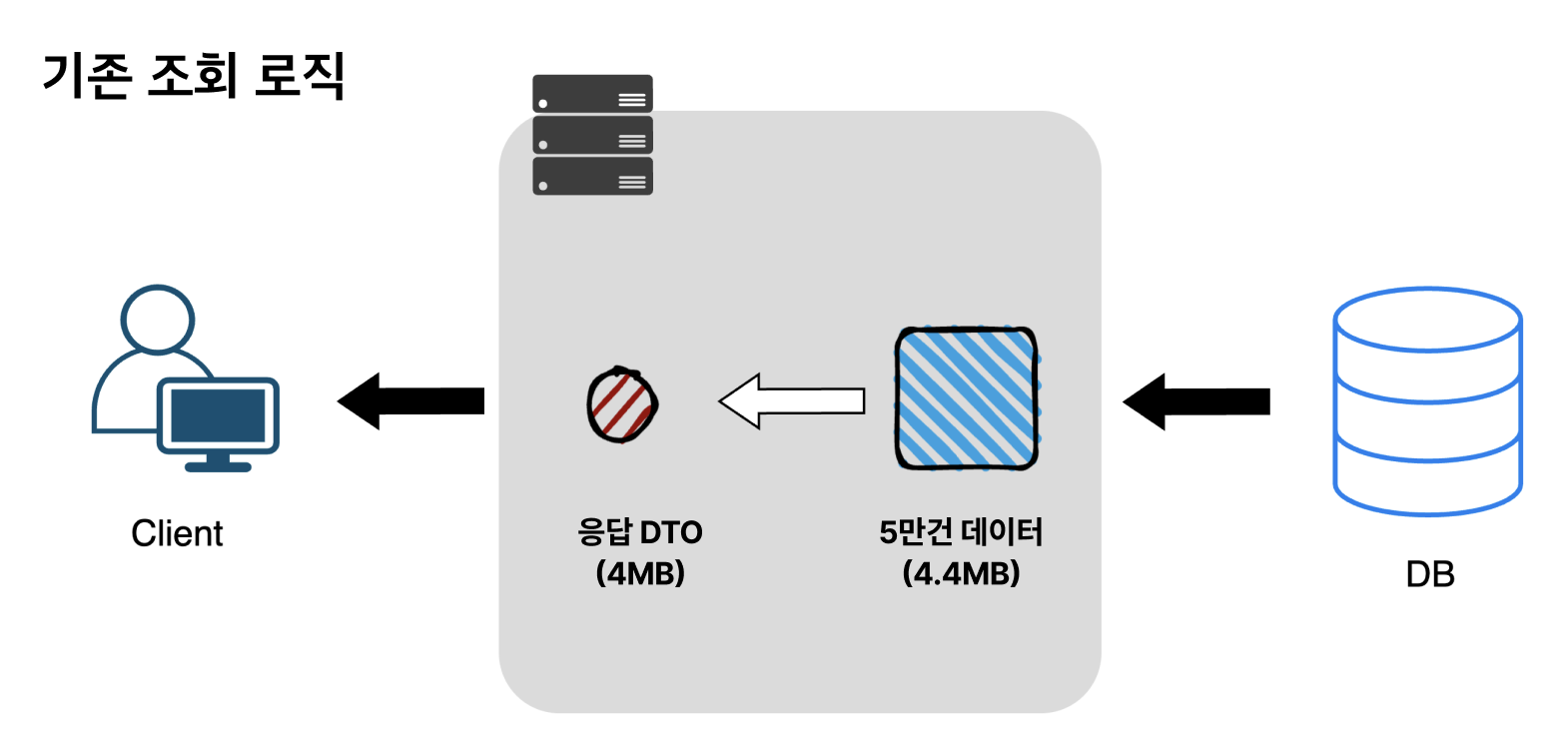
5-1의 프로젝션을 사용한 방식의 메모리 사용량은 아래와 같습니다.
최대 메모리 사용량 : 약 8.4MB (조회한 데이터 5만건 4.4MB + 응답 DTO 4MB)
그럼 Stream 방식은 어떻게 바뀔까요?
Stream 방식

구현코드
@Query("""
SELECT new com.softeer5.uniro_backend.map.service.vo.LightRoute(r.id, r.distance, n1, n2)
FROM Route r
JOIN r.node1 n1
JOIN r.node2 n2
WHERE r.univId = :univId
""")
@QueryHints(value = {
@QueryHint(name = "org.hibernate.fetchSize", value = Integer.MIN_VALUE + ""),
@QueryHint(name = "org.hibernate.cacheable", value = "false")
})
Stream<LightRoute> findAllLightRoutesByUnivId(Long univId);
저희 조회로직이 단순 조회가 아닌 비즈니스 로직 처리도 필요했습니다.
그래서 특정 Batch 단위만큼 쌓이게 되면, 비즈니스 로직을 실행시키도록 구현해봤습니다.
먼저 Stream 방식을 활용하여 메모리에 한 건씩 적재합니다.
그러다 특정 Batch 단위만큼 쌓이게 되면, 조합해주는 비즈니스 로직을 실행시켜 응답 DTO 일부를 만들어줍니다.
위의 예시에서는 1/4 단위 만큼 쌓였을 때, 비즈니스 로직을 실행시켜 기존 응답 DTO(4MB) 의 1/4 인 1MB 응답 DTO를 만듭니다.

모든 데이터를 다 처리하게 되면, 기존 로직과 똑같이 4MB 응답 DTO를 만들게 됩니다.
기존 방식 vs Stream 방식의 메모리 사용 비교
데이터를 처리한 후 최종적으로 응답 DTO 크기가 4MB라는 점은 기존 방식과 Stream 방식 모두 동일합니다.
하지만 DB에서 객체를 불러올 때 메모리 사용량에서 큰 차이가 발생합니다.
1️⃣ 기존 방식
한 번의 쿼리 실행으로 모든 데이터를 메모리에 로드합니다. 즉, DB에서 불러온 객체 전체(4MB)가 한꺼번에 메모리에 적재됩니다.
그 후, 응답 DTO(4MB)를 생성하여 반환합니다.
결과적으로, 최대 메모리 사용량 = 8MB 가 됩니다.
(DB에서 불러온 객체 4MB + 응답 DTO 4MB)
2️⃣ Stream 방식
DB에서 데이터를 한 건씩 순차적으로 읽고 처리합니다.
특정 개수(예: 1MB 크기 이상의 객체)가 쌓이면, 비즈니스 로직 실행 후 해당 객체를 즉시 메모리에서 해제합니다.
따라서, DB에서 불러온 객체가 메모리에 유지되는 최대 크기는 1MB 수준이 됩니다.
그 후, 응답 DTO(4MB)를 생성하여 반환합니다.
결과적으로, 최대 메모리 사용량 = 5MB 가 됩니다.
(DB에서 불러온 객체 1MB + 응답 DTO 4MB)
최대 메모리 사용량 비교
| 불러오는 최대 객체 | 응답 DTO | 총합 | |
| 기존 방식 | 4MB (전체 데이터 적재) | 4MB | 8MB |
| Stream 방식 | 1MB (순차 처리 후 해제) | 4MB | 5MB |
이처럼 Stream 방식은 메모리 사용량 절감에 큰 도움이 됩니다.
현재 예시는 설명을 쉽게 하기 위해 1/4 로 했지만 실제 구현해서는 더 작은 단위로 나눠 메모리 사용량의 차이가 굉장히 큽니다.
당연한 얘기지만, GC 측면에서도 필요한 객체만 유지하고 즉시 해제하기 때문에 GC 부담이 줄어드는 장점이 있습니다.
5-3. 프로젝션 + Stream 방식 효과

결과는 성공 !!
그래프와 같이 똑같은 부하를 줬는데 메모리 사용량에 있어 굉장히 안정적인 그래프가 되었습니다.
뿐만 아니라 이제 아무리 큰 부하를 주더라도 OOM 문제가 발생하지 않게 되었습니다.
5-4. 더 개선 해볼까? - SSE 방식
저희는 충분히 좋은 결과를 얻었지만, 더 나은 개선 방안을 고민했습니다.
현재 구조에서는 Stream을 활용하여 Batch 단위로 객체를 읽고 있습니다.
하지만 최종적으로 클라이언트에 응답을 보내기 위해서는, 이렇게 분할된 DTO를 모두 모아 하나의 응답으로 만들어야 합니다.
이 과정에서 메모리 사용량을 더욱 줄일 수 있는 방법이 없을까? 라는 고민이 들었습니다.
만들어진 DTO를 바로 전송하면 어떨까?
기존 방식처럼 한 번에 데이터를 모아 전달하는 것이 아니라, 생성 즉시 클라이언트로 보내면 어떨까? 하는 아이디어가 논의되었습니다.
이를 기반으로 스트리밍 방식과 SSE(Server-Sent Events) 를 결합한 방식을 도입해 보았습니다.

기존 방식에서는 Stream을 활용해 Batch 단위(1MB) 로 데이터를 읽고, 모든 응답 DTO를 모아둔 후 한 번에 클라이언트로 전송했습니다.
그러나 새로운 방식에서는 SSE를 활용하여 DTO가 생성되는 즉시 클라이언트로 전송하도록 변경했습니다.
즉, 클라이언트는 기존처럼 한 번에 모든 데이터를 받는 것이 아니라, 4번에 걸쳐 나눠서 응답을 받게 됩니다.
이 방식의 장점은 다음과 같습니다.
- 메모리 사용량 절감: 서버가 응답 DTO를 오래 가지고 있을 필요 없이 즉시 전송하므로, 여유 메모리를 확보할 수 있습니다.
- 빠른 응답 제공: 클라이언트가 데이터를 더 빨리 받을 수 있어 UX가 개선됩니다.
다행히 클라이언트에서도 이 변경을 큰 수정 없이 적용할 수 있었기 때문에, 바로 구현을 진행할 수 있었습니다.
기존방식 vs Stream 방식 vs Stream + SSE 방식의 메모리 사용 비교
| 불러오는 최대 객체 | 응답 DTO | 총합 | |
| 기존 방식 | 4MB (전체 데이터 적재) | 4MB | 8MB |
| Stream 방식 | 1MB (순차 처리 후 해제) | 4MB | 5MB |
| Stream + SSE 방식 | 1MB (순차 처리 후 해제) | 1MB (순차 처리 후 해제) | 2MB |
5-5. 프로젝션 + Stream +SSE 방식 효과

결과는 성공 !!
전체적인 메모리 사용량이 드라마틱하게 개선된 것을 확인할 수 있습니다 !!
UX 개선
메모리 사용량 뿐만 아니라 UX적으로도 사용자가 첫 화면을 훨씬 빠르게 볼 수 있게 되었습니다.
(더 선명한 차이를 보여주기 위해 재생속도를 늦췄습니다.)
왼쪽이 기존 버전, 오른쪽이 SSE를 적용한 버전입니다.
보시다시피, SSE를 적용한 오른쪽 버전은 나중에 생성되는 길이 조금 있긴 합니다.
하지만 사용자 입장에서 크게 어색하지 않고, 첫 화면도 훨씬 빠르게 볼 수 있게 되었습니다!!
6. 결론 & 다음편 예고
사실 500MB의 서버는 실제 서비스를 하는 서버를 생각해보면 너무나도 작은 수치입니다.
그래서 이렇게 분석하는 것이 어떤 의미가 있을까 생각할 수 있습니다.
하지만 결국 성능이 좋은 서버도 전국 단위로 서비스를 한다면, 똑같이 메모리의 문제를 맞이하게 될 것입니다.
실무에서도 저희와 비슷한 서비스를 하는 곳들은 비슷한 고민을 하지않을까 생각이 듭니다!
(나중에 이 쪽 도메인에 계신 분들께 여쭤보고 싶네요 ㅎㅎ)
사실 이 위의 과정은 제가 보조적인 역할을 하였고, 메인 구현은 다른 팀원분이 맡아주셨습니다.
하지만 기술을 선택하는 의사결정 단계에서 항상 함께 고민을 하였고, 구현 관련해서도 지속적으로 sync를 맞춰나갔기 때문에 이제는 마치 제가 구현한 것처럼 아주 충분한 설명을 할 수 있게 된 것 같습니다.
다음 시간에는 제가 메인으로 구현했던 응답속도 개선 파트입니다.
현재까진 메모리 사용량에 초점을 맞췄다면, 이젠 핵심로직인 만큼 해당 로직의 응답속도를 개선한 과정을 설명드려보겠습니다!
[다음 포스팅]
https://gamxong.tistory.com/161
[소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 2편
1. 시작하면서이전 글에서는 OOM 문제를 해결하면서 메모리 사용량에 집중해봤습니다. 2025.03.08 - [BE/Spring] - [소프티어] 5만건 데이터, OOM 문제부터 160ms까지 개선 - 1편 [소프티어] 5만건 데이터, OO
gamxong.tistory.com
'BE > Spring' 카테고리의 다른 글
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 3편 (5) | 2025.03.25 |
|---|---|
| 5만건 데이터, OOM 문제부터 110ms까지 개선 - 2편 (4) | 2025.03.08 |
| [Spring] 10만 요청으로 서버 장애부터, 응답시간 80% 개선까지 (1) | 2025.01.14 |
| [Spring] 빈, 컨테이너 그게 뭔데? (1) | 2023.07.18 |




댓글