오늘은 구글이 만든 AI 전용 칩, TPU의 내부 구조(MXU, VPU, VMEM)와 이들이 거대한 슈퍼컴퓨터로 연결되는 방식에 대해 알아보겠습니다.
1. TPU의 내부 구조: 3가지 핵심 부품
TPU 칩 안을 들여다보면, 크게 세 가지 핵심 유닛이 쉴 새 없이 돌아가고 있습니다.
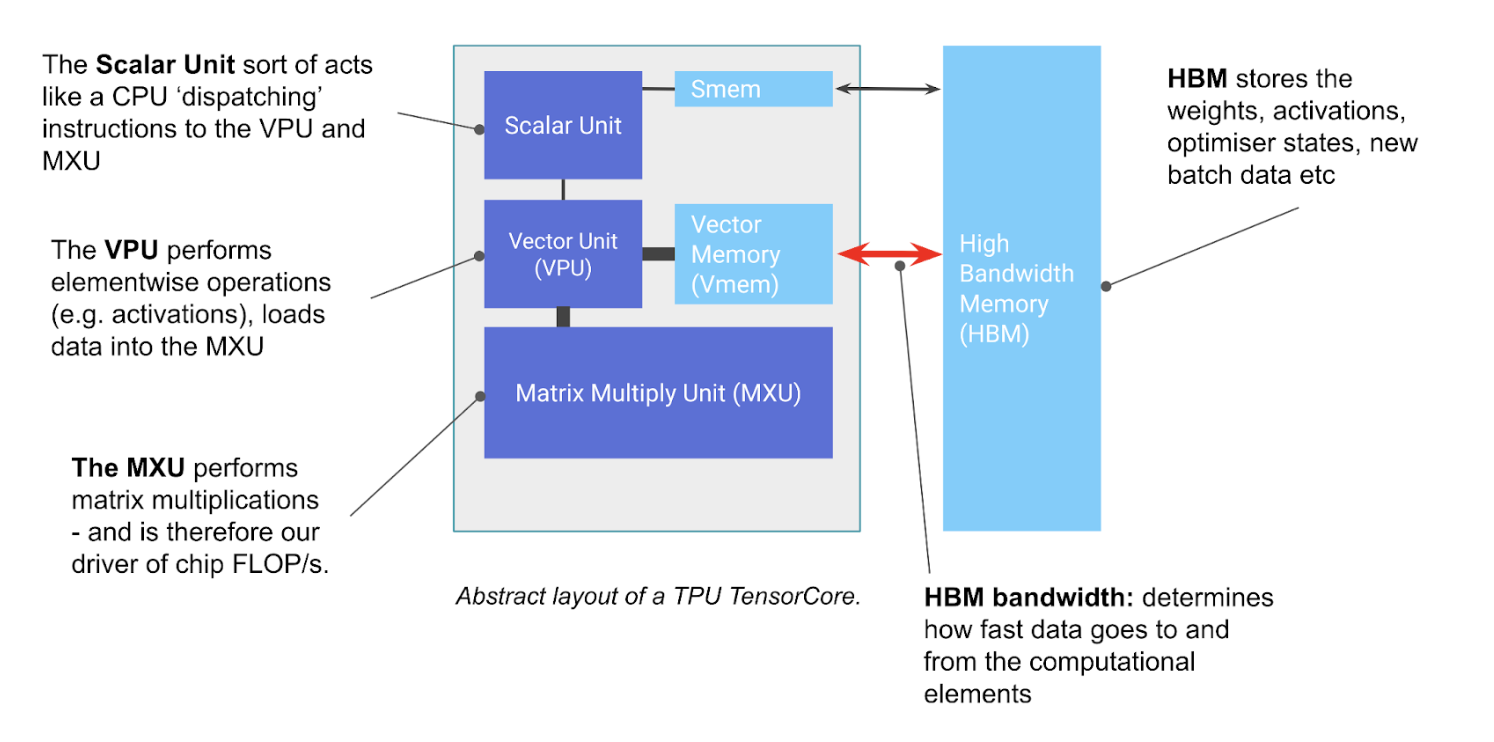
1. MXU (Matrix Multiply Unit)
- 역할: TPU의 존재 이유입니다. 오직 행렬 곱셈만을 위해 태어난 장치입니다.
- 특징: 시스톨릭 어레이(Systolic Array) 구조를 사용합니다. (뒤에서 자세히 설명)
- 성능: TPU v5e 기준으로 코어당 초당 약 200조 번(2e14)의 연산을 수행합니다.
2. VPU (Vector Processing Unit)
- 역할: 행렬 곱셈 이외의 일반적인 계산을 담당합니다.
- 작업: 활성화 함수(ReLU 등), 벡터 간 덧셈/곱셈, 합계 구하기(Reduction) 등.
3. VMEM (Vector Memory)
- 역할: 칩 내부에 있는 작은 임시 저장소입니다.
- 중요성: HBM(메인 메모리)보다 용량은 작지만(약 128MB), 속도(대역폭)는 훨씬 빠릅니다.
- 핵심: MXU는 HBM에 있는 데이터를 직접 건드릴 수 없습니다. 반드시 HBM → VMEM으로 데이터를 복사해온 뒤에야 연산이 가능합니다.
2. 데이터의 흐름: HBM과 병목 현상
TPU의 작업 흐름은 다음과 같습니다.
- HBM에 있는 거대한 데이터를 VMEM으로 가져옵니다.
- MXU가 VMEM에 있는 데이터를 가져와 미친 듯이 곱셈을 합니다.
- 결과를 다시 VMEM에 썼다가, HBM으로 돌려보냅니다.
💡 여기서 성능의 핵심!
VMEM의 대역폭은 HBM보다 약 22배나 빠릅니다.
따라서 데이터를 HBM에서 가져오는 횟수를 줄이고, 한 번 VMEM에 가져온 데이터를 최대한 재사용(Reuse)해야 최고의 성능을 낼 수 있습니다. (이것이 이전 글에서 말한 '산술 강도'를 높이는 방법입니다.)
3. TPU 네트워킹: 칩들은 어떻게 대화하는가?
TPU 하나만으로는 거대 모델을 감당할 수 없습니다. 수천 개의 TPU를 연결해야 하는데, 이때 연결 방식이 GPU와는 조금 다릅니다.
1. ICI (Inter-Chip Interconnect)
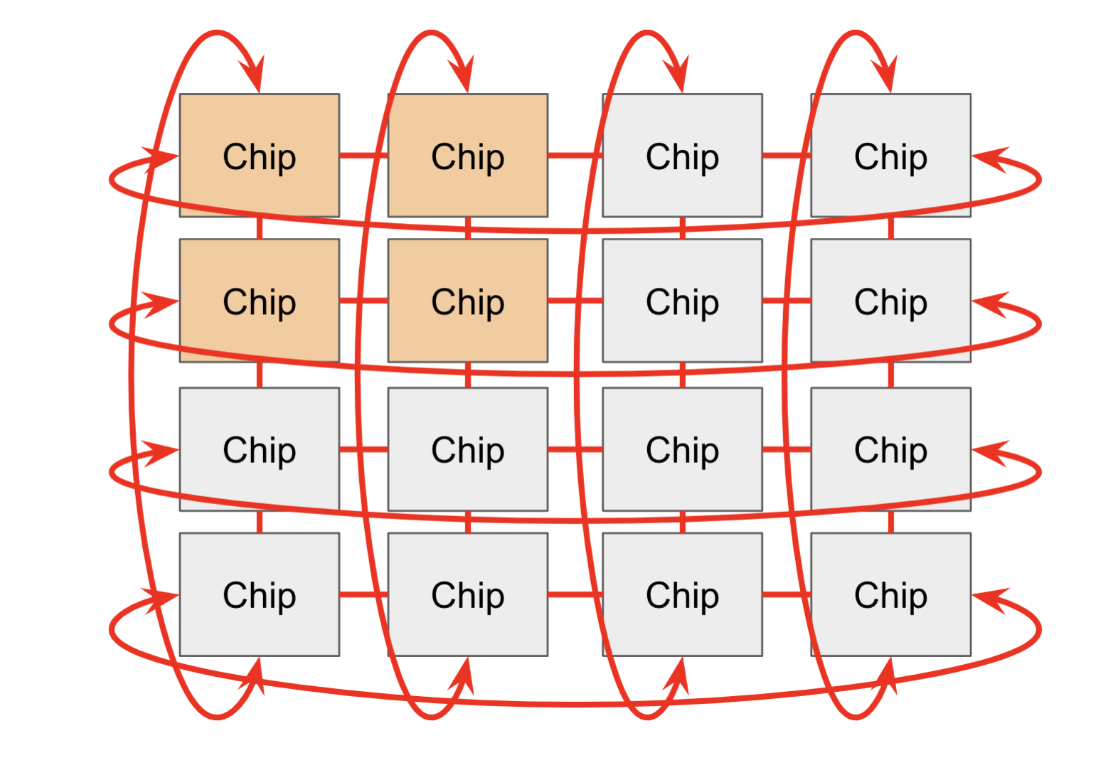
- 방식: TPU 칩끼리 직접 연결된 초고속 네트워크입니다.
- 구조: 토러스(Torus) 구조를 사용합니다. 즉, 내 옆, 위, 아래에 있는 이웃 칩들과 직접 손을 잡고 있는 형태입니다. (GPU가 복잡한 스위치 장비를 통해 연결되는 것과 대조적입니다.)
- 장점: 스위치 같은 중계 장비가 필요 없어 구조가 단순하고 확장이 쉽습니다.
2. DCN (Data Center Network)
- 방식: TPU 묶음(Pod)과 다른 Pod, 혹은 CPU 호스트끼리 통신하는 일반적인 데이터센터 네트워크입니다.
- 속도: ICI보다 훨씬 느립니다. 따라서 모델을 쪼갤 때, 빈번한 통신은 ICI로 해결하고 DCN 사용은 최소화해야 합니다.
3. PCIe : 호스트와의 연결
- 방식: CPU(주인)와 TPU(가속기)를 연결하는 통로입니다.
- 속도: 가장 느립니다. HBM 대역폭보다 약 100배 느립니다. 데이터를 CPU에서 TPU로 옮기는 건 꽤 시간이 걸리는 일입니다.
4. 심화: 시스톨릭 어레이 (Systolic Array)란?
MXU가 행렬 곱셈을 처리하는 방식인 '시스톨릭 어레이'는 TPU의 가장 큰 특징입니다.
- 의미: 'Systolic'은 심장 박동(수축)을 뜻합니다. 데이터가 심장 박동처럼 리듬에 맞춰 흐른다는 뜻입니다.
- 작동 원리:
- 일반적인 CPU/GPU는 데이터를 레지스터에서 가져와서 계산하고 다시 저장합니다. (Load-Store 방식)
- 시스톨릭 어레이는 데이터가 수만 개의 연산 유닛(ALU) 사이를 물 흐르듯이 통과합니다.
- 왼쪽에서 데이터가 들어오고, 위에서 가중치가 내려오면서, 교차점에서 곱해지고 더해지며 옆으로 전달됩니다.
- 장점: 데이터를 한 번 읽어서 수만 번 재사용하므로 에너지 효율과 연산 밀도가 압도적으로 높습니다.
5. 핵심 요약
- TPU는 단순합니다: 거대한 행렬 곱셈 기계(MXU)에 초고속 메모리(HBM)를 붙여놓은 것입니다.
- 속도의 계급도:
- VMEM ↔ MXU: 빛의 속도 (가장 빠름)
- HBM ↔ VMEM: 고속도로 (빠름, 하지만 병목의 주원인)
- ICI (칩 간 통신): 국도 (꽤 빠름)
- DCN/PCIe: 비포장도로 (느림, 최대한 피해야 함)
- 최적화의 목표: 느린 HBM이나 네트워크를 기다리느라 빠른 MXU가 노는 일이 없도록, 데이터 이동과 연산을 겹쳐서(Overlap) 수행하는 것입니다.
이 글은 Google Cloud TPU 아키텍처 기술 문서를 바탕으로 재구성되었습니다.
'AI > GPU' 카테고리의 다른 글
| 3. Sharded Matrices and How to Multiply Them (0) | 2026.02.22 |
|---|---|
| 1. Rooflines에 관한 모든것 (1) | 2026.01.25 |


댓글