
Java는 많이 사용하지만 Java 힙에서 객체 생성부터 전 과정에 대해서는 알지 못했습니다. 그래서 전 과정에 대해 구체적으로 알아보고자 합니다. 책 JVM 밑바닥까지 파헤치기의 내용을 참고했지만, 더 쉬운 이해를 위해 제가 각색하고 내용을 추가해봤습니다.
1. 객체 생성
언어 수준에서는 단순히 new 키워드를 사용하면 됩니다.
가상 머신 수준에서는 어떤 과정을 거쳐 객체가 생성될까요?
JVM이 new 명령에 해당하는 바이트 코드를 만난다면, 이 명령의 매개변수가 상수 풀 안의 클래스를 가리키는 심벌 참조(Symbolic Reference)인지 확인합니다. 이 과정을 구체적으로 설명해보겠습니다.
먼저 아래와 같은 코드가 있다고 가정해보겠습니다.
public class Example {
public static void main(String[] args) {
MyObject obj = new MyObject();
}
}
class MyObject {
public MyObject() {
System.out.println("MyObject created");
}
}
이 코드를 컴파일하면, 다음과 같은 JVM 바이트코드를 얻을 수 있습니다.
public static void main(java.lang.String[]);
Code:
0: new #2 // 참조: MyObject
3: dup
4: invokespecial #3 // 참조: MyObject.<init>
7: astore_1
8: return
여기서 new 명령은 상수 풀 #2에 저장된 MyObject에 대한 심벌 참조를 가리킵니다. 이 MyObject 클래스가 로드되지 않은 상태라면, JVM은 클래스 로더를 사용해 심벌 참조를 실제 메모리 상의 클래스 객체로 변환합니다.
로딩이 완료된 클래스라면, 새 객체를 담을 메모리를 할당합니다.
객체에 필요한 메모리 크기는 클래스를 로딩후에 알 수 있습니다.
보통 자바의 힙은 규칙적이지 않습니다. 따라서 JVM은 가용 메모리 블록들을 목록으로 관리하여 특정 객체 메모리를 할당할 때 충분한 공간을 찾아 할당합니다. 이러한 방식을 free list 라고 합니다.
멀티 스레딩 환경에서 공간 할당 방법
단일 스레드가 아닌 멀티 스레딩 환경에서는 여러 스레드가 동시에 객체를 생성할 때 문제가 생길 수 있습니다.
예를 들어, 하나의 스레드가 A 객체의 메모리 할당을 하는 과정에서, 다른 스레드가 B 객체를 할당할 수도 있기 때문입니다.
이를 위해 2가지 해결 방법이 있습니다.
첫 번째는 메모리 할당을 동기화하는 것입니다.
실제로 비교 및 교환과 실패시 재시도 하여 원자적으로 수행하는 방식입니다.
두 번째는 스레드마다 다른 메모리 공간을 할당하는 것입니다.
스레드 각각 힙 내의 작은 크기의 전용 메모리를 할당 받아 놓는 것입니다. 이런 메모리를 스레드 로컬 할당 버퍼(TLAB, thread local allocation buffer) 라고 합니다. 각 스레드는 로컬 버퍼에서 메모리를 할당 받아 사용하다가 버퍼가 부족해지면 그때 동기화를 해 새로운 버퍼를 할당받는 방식입니다.

이렇게 메모리 할당이 끝나면, JVM 관점에서는 새로운 객체가 다 만들어졌다고 볼 수 있습니다. 하지만 자바 프로그램 관점에서는 그렇지 않습니다. 그래서 JVM은 class의 init메소드를 실행합니다. init()메소드까지 실행되어야 개발자의 의도대로 비로소 사용 가능한 진짜 객체가 완성됩니다.
자바 컴파일러는 new 키워드를 발견하면 위 바이트코드와 같이 명령어 new와 invokespecial로 변환합니다. new는 앞서 이야기한 메모리 할당을 의미하며, invokespcial은 init()메소드 호출을 담당합니다. new가 아닌 다른 방식으로 객체가 생성되면 init()이 실행되지 않을 수 있습니다.
2. 객체의 메모리 레이아웃
핫스팟 JVM 에서는 객체를 세 부분으로 나눠 저장합니다.

1. 객체 헤더
- 마크 워드 : 객체의 런타임 데이터(해시코드, GC세대 나이, 락 정보)
- 클래스 워드(klass word) : 클래스 관련 메타데이터를 가리키는 클래스 포인터
- 배열 길이 : 배열객체일 경우 사용
2. 인스턴스 데이터 : 객체가 실제로 담고 있는 정보(필드, 함수)
(+XX:CompactFields 매개변수를 true로 설정하면 하위 클래스의 필드 중 길이가 짧은 것들은 상위 클래스 변수 사이사이에 끼워져서 공간이 조금 절약됩니다.)
3. 정렬 패딩 : 전체 크기가 8바이트의 정수배가 되도록 자리 확보하는 역할입니다.
3. 객체에 접근하기
대다수의 객체는 다른 객체 여러 개를 참조하여 만들어집니다. JVM마다 객체 내 참조 객체에 접근하는 방법이 다르며, 주로 핸들이나 다이렉트 포인터를 사용합니다.
핸들 방식
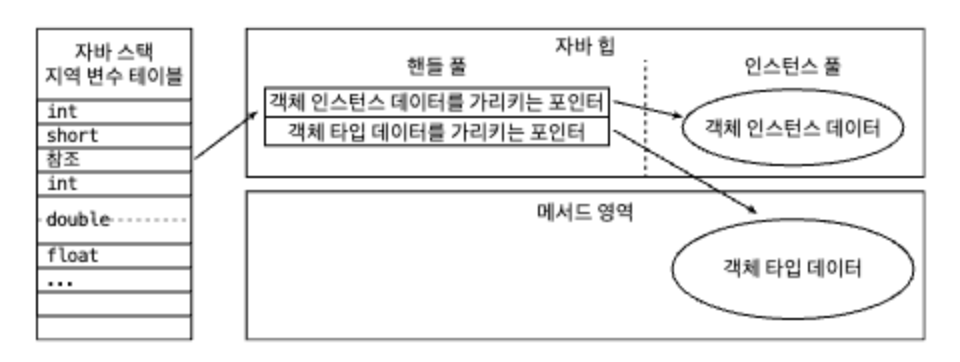
자바 힙에 핸들 저장용 풀이 별도로 존재합니다. 참조에는 객체의 핸들 주소가 저장되고 핸들에는 다시 해당 객체의 인스턴스 데이터, 타입데이터, 구조 등의 정확한 주소 정보가 담깁니다.
장점 : 참조에 안정적인 핸들의 주소가 저장됩니다. GC 중에는 객체의 위치가 자주 바뀌게 됩니다. 그런 상황에서도 참조 자체에는 손댈 필요가 없게 됩니다. 그 대신 핸들내의 인스턴스 데이터 포인터만 변경하면 됩니다.
다이렉트 포인터 방식
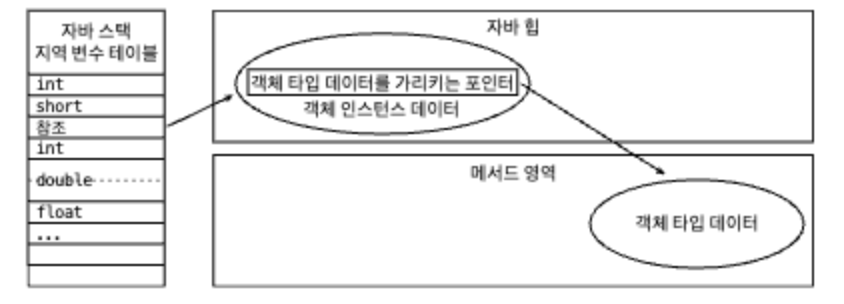
다이렉트 포인트 방식에서는 자바 힙에 위치한 객체에서 인스턴스 데이터뿐 아니라 타입 데이터에 접근하는 길도 제공해야 합니다.
장점 : 스택의 참조에는 객체의 실제 주소가 바로 저장되어 있어 빠른 접근이 가능합니다. (핫스팟은 주로 다이렉트 포인터 방식을 사용)
출처:
책 - JVM 밑바닥까지 파헤치기
'BE > JVM' 카테고리의 다른 글
| 가비지 컬렉터와 메모리 할당 전략 - 1. 죽은 객체 판단 (0) | 2024.12.22 |
|---|

댓글