0. 목표
- graphQL이 무엇인지 누구한테 간단히 말할 수 있을 정도로 알아보자.
- graphQL를 통해서 실제 개발은 어떤식으로 하는지 감각을 가져보자.
1. GraphQL 그게 뭔데
1-1. 일단 REST API ?
REST API에 대해서는 깊게 들어가면 끝이 없지만 다들 어느정도 알고 계시기도 하고, 이게 중요한게 아니니까 REST API 자체에 대한 자세한 설명은 넘어가겠습니다!
1-2. REST API 한계
OverFetching 문제
특정 API 의 응답값이 다음과 같다고 가정해보겠습니다!
[
{
"name": "송민규",
"nickname" : "송민규짱짱맨",
"generation" : 33,
"part" : "server",
"drinkingCapacity" : 2.5
"mbti": "ENTJ"
},
{
"name": "홍길동",
"nickname" : "홍길이",
"generation" : 32,
"part" : "server",
"drinkingCapacity" : 7.5
"mbti": "CUTE"
},
{
"name": "원윤이",
"nickname" : "워뉴니",
"generation" : 31,
"part" : "IOS",
"drinkingCapacity" : 0.1
"mbti": "ISFP"
},
// ...
]
만약 특정 화면을 출력하기 위해 name 과 part 만 필요하다면?
- BE 에서 새로운 API 를 만들어준다.
- → 새로운 API를 만드는데 필요한 리소스, 현실적으로 모든 모든 API를 커스텀하긴 힘듦
- → BE 코드 중복 발생으로 인한 유지보수의 어려움
- FE 에서 같은 API를 사용하되, 받은 데이터 중 name 과 part 만 사용한다.
- → OverFetching 문제 발생 : 필요없는 데이터까지 리턴받아 통신 비용 증가
- → 보안적으로도 문제 있을수도!
UnderFetching 문제
특정 화면을 출력하기 위해선 다음과 같은 데이터가 필요하다고 가정해보겠습니다!
{
"partLeader": "최윤한",
"members": [
{
"name": "송민규",
"mbti": "ENTJ",
"studyParticipationCount" : 3
},
{
"name": "규민송",
"mbti": "ENTJ",
"studyParticipationCount" : 15
},
{
"name": "민송규",
"mbti": "ISFJ",
"studyParticipationCount" : 7
},
//...
]
}이 데이터를 얻기 위해서는 이전 API와 또다른 API를 조합하여 해당 데이터 구조를 만들 수 있을 것입니다!
다시 말해, 2번 이상의 API 요청이 필요합니다!
→ OverFetching 문제와 비슷한 맥락으로 통신 비용이 증가하는 단점을 가지고 있습니다.
1-3. GraphQL
- GraphQL(이하 gql)도 다른 SQL(이하 sql)과 마찬가지로 쿼리언어입니다.
- 하지만 gql과 sql은 언어적 구조 차이가 매우 큽니다.
| sql | gql | |
| 목적 | 데이터베이스 시스템에 저장된 데이터를 효율적으로 가져온다. | 웹 클라이언트가 데이터를 서버로부터 효율적으로 가져온다. |
| 사용주체 | 백엔드 시스템 | 클라이언트 시스템 |
- sql이 아래와 같다면,
SELECT name, mbti, generation FROM members;
- gql은 아래와 같습니다!
query {
members {
name
mbti
generation
}
}
❓클라이언트가 이렇게 보내면, 서버에서는 뭘하는거지?
- 서버는 gql로 작성된 쿼리를 클라이언트로부터 입력 받아 DB로 쿼리(SQL)를 처리한 결과를 다시 클라이언트로 돌려줍니다.

REST API와 비교
| REST API | GQL API |
| 다양한 Endpoint 존재 | 단 하나의 Endpoint |
| Endpoint마다 데이터베이스 SQL 쿼리가 달라짐 | gql 스키마의 타입마다 데이터베이스 SQL 쿼리가 달라짐 |
1-4. 그래서 성능이 실제로 어느정도인데?
- 페이스북 또는 넷플릭스가 어느정도의 성능 최적화를 이뤄냈는지 궁금했는데 관련 지표는 역시 찾기 어렵군요..
2. BE 입장에서 GraphQL 맛보기
“뭐 좋은거 알겠는데, 그래서 백엔드는 뭐가 달라지는거야?”
- 저는 아무래도 백엔드쪽이다 보니까 백엔드 입장에서 실제로 어떻게 사용해야하는지, 기존과 얼마나 다른지, 어떻게 구현되는지 궁금했습니다.
2-1. 아키텍처
- 큰 그림에서의 아키텍처는 기존 REST API를 사용했을 때와 동일한 패턴입니다!
- 물론 세부적으로는 리졸버 함수 때문에 다르겠지만 앞단에서만 조금 달라질 뿐 서비스 로직부터는 크게 다르지 않습니다.
2-2. 아주 살짝 맛보기 - Spring for GraphQL 사용
- 나름 최근에 Spring에서 공식 릴리즈한 프로젝트입니다.
- 이전에 나온 라이브러리/프레임워크를 사용하면 Resolver를 개발하고 별도의 설정 등 필요했습니다.
- 하지만 Spring for GraphQL은 Spring이 추구하는 방향답게 추가적인 코드 없이 기존 MVC 개발하듯 개발하면 됩니다!
Query & Mutation
- 등록, 수정, 삭제, 조회를 구분하는 방법입니다.
- 조회 : Query
- 등록, 삭제, 수정 : Mutation
Controller
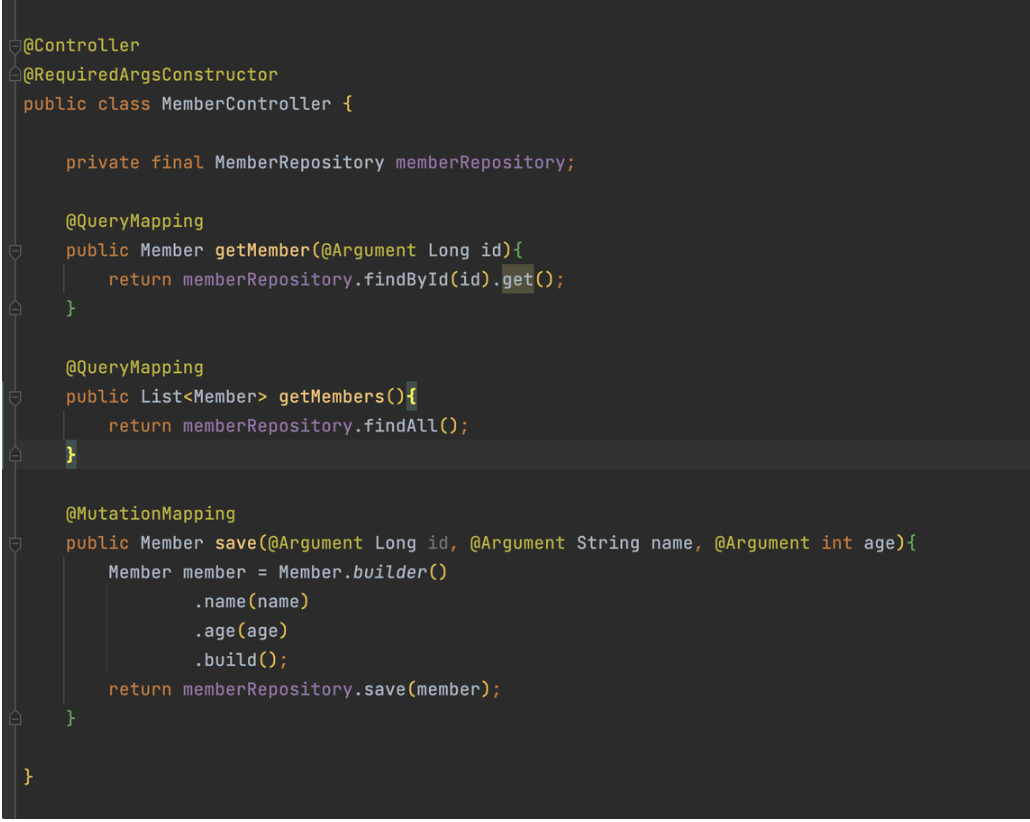
- 이처럼 어노테이션 기반으로 코드 작성이 가능합니다!
- @Argument :
- @RequestBody 와 비슷한 역할을 한다고 생각했습니다!
- gql을 통해 전달되는 인수를 매핑하는 역할을 하는 것 같습니다!
- @QueryMapping :
- @GetMapping 과 비슷한 역할을 합니다.
- @MutationMapping :
- Get를 제외(등록, 수정, 삭제)한 것들에 해당합니다!
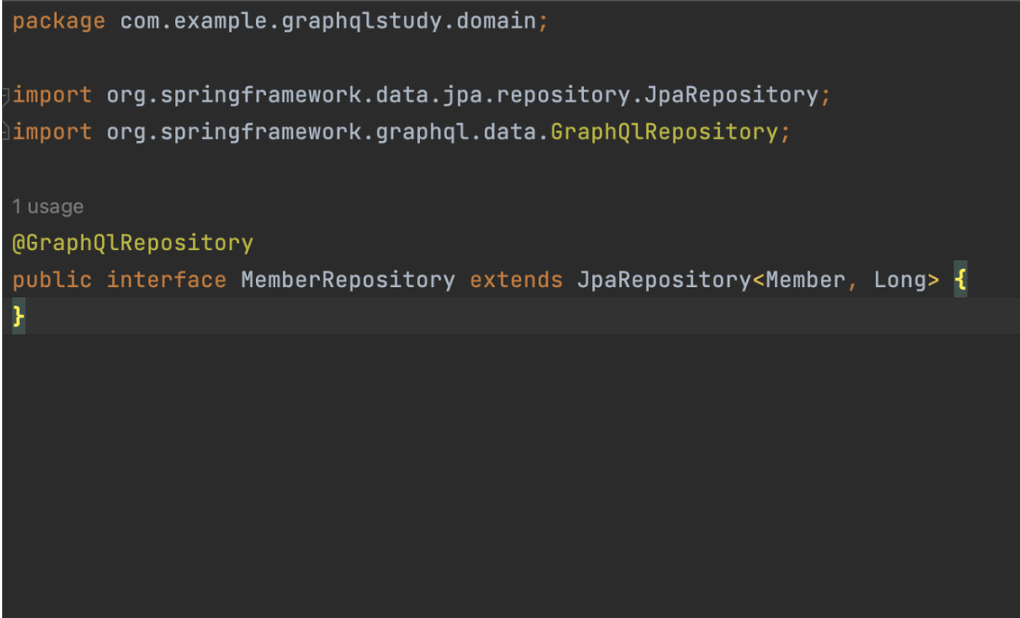
Repository
Schema
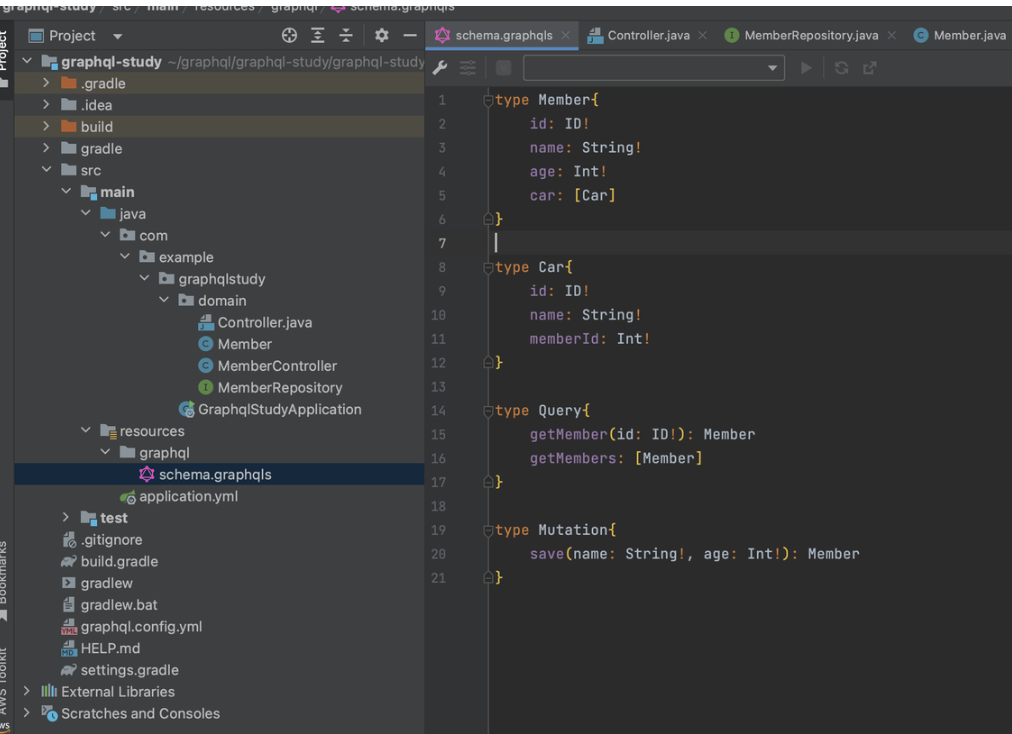
- graphql을 사용하기 전에 schema를 설정해야 합니다!
- schema.graphqls 파일을 만들고 거기에 스키마를 설정해놓으면, spring-boot-graphql 이 컨트롤러에서 받은 요청을 자동으로 매핑시킨다.
3. 정리
3-1. 느낀점
- 사실 그렇게 깊게 들어가진 않고, 가볍게 알아봤는데요!
- 저는 사실 만약 graphQL이 기존에 제가 해왔던 방식과 크게 다르다면, 사용하는 것에 살짝은 부정적일 수도 있었을 것 같아요!
- 하지만 전체적인 플로우를 보고 완전 새로운 것이 아닌, 기존의 방식에서의 개선한 느낌이라 좋았던 것 같아요.
- 대충 코드를 보시면 아시겠지만 서비스 로직 자체는 이전에 REST API 개발때와 크게 다르지 않다는 것을 알 수 있습니다!
- 즉, 제가 하고 싶은 말은 물론 GraphQL에 대해 배워야 하는 러닝커브가 있는 것은 사실이지만 본질적으로는 크게 다르지 않다! 라는 것을 얘기해보고 싶었습니다!
- 크게 다르지 않지만, REST API 의 문제점을 해결해주는 솔루션이 될 수 있기에 도입해보는 것도 좋겠다라고 생각했습니다!
3-2. TradeOff
- GraphQL 스키마의 유지보수 : 서버 개발자로서 유지보수 포인트가 늘어난 건 맞는 것 같습니다!
- 서버 개발자의 노력이 더 필요하게 된다.
- 캐싱 전략이 RESTful API에 비해 어렵다. (이 말은 사실 크게 와닿지는 않았습니다..!)
- 학습 곡선이 있다.(기존 RESTful API 보다)
참고자료
Annotated Controllers :: Spring GraphQL
댓글