1. 목적
- 데이터 값을 계산하거나 조작 (단일 행 함수)
- 행의 그룹에 대해 계산하거나 요약 (그룹 함수)
- 열의 데이터 타입을 변환
단일 행 함수 : 한 번에 하나의 데이터를 처리하는 함수
그룹 함수 : 여러 건의 데이터를 동시에 처리하여 해당 그룹에 해당하는 결과를 반환
해당 열에 있는 데이터를 모아 결괏값을 출력
2. 단일 행 함수
데이터 타입의 종류
저장 데이터 데이터 타입 설명
| 문자 | CHAR(n) | n 크기만큼 고정 길이의 문자 타입을 저장 |
| 문자 | VARCHAR2(n) | n 크기만큼 가변 길이의 문자 타입을 저장 |
| 숫자 | NUMBER(p,s) | 숫자 타입을 저장 (p: 정수 자릿수, s : 소수 자릿수) |
| 날짜 | DATE | 날짜 타입을 저장 |
단일 행 함수의 종류
종류 설명
| 문자 타입 함수 | 문자를 입력받아 문자와 숫자를 반환 |
| 날짜 타입 함수 | 날짜에 대한 연산 |
| 숫자를 반환하는 MONTHS_BETWEEN 함수를 제외한 모든 날짜 타입 함수는 날짜 값을 반환 | |
| 변환 타입 함수 | 임의의 데이터 타입의 값을 다른 데이터 타입으로 변환 |
| 일반 함수 | 그 외 NVL, DECODE, CASE, WHEN, 순위함수 등 |
단일 행 함수의 특징
- 각 행에 대해 수행
- 데이터 타입에 맞는 함수를 사용해야 함
- 행별로 하나의 결과를 반환
- SELECT, WHERE, ORDER BY 절 등에서 사용가능
- 함수 속의 함수처럼 중첩 사용 가능
- 중첩 사용할 경우 안쪽단계에서 바깥단계 순으로 진행
2-1. 문자 타입 함수
💡 문자나 문자열 데이터는 작은따옴표(’)로 묶어서 문자 타입으로 표현

LOWER, UPPER, INITCAP
예제 : employees 테이블에서 last_name을 소문자와 대문자로 각각 출력하고, email의 첫 번째 문자는 대문자로 출력
SELECT last_name,
LOWER(last_name),
UPPER(last_name),
email,
INITCAP(email)
FROM employees;
SUBSTR
예제 : employees 테이블에서 job_id 데이터 값의 첫째 자리부터 시작해서 두 개의 문자를 출력
SELECT job_id, SUBSTR(job_id, 1, 2)
FROM employees;
REPLACE
예제 : employees 테이블에서 job_id 문자열 값이 ACCUONT면 ACCNT로 출력
SELECT job_id, REPLACE(job_id, 'ACCOUNT', 'ACCNT')
FROM employees;
LPAD, RPAD
예제 : employees 테이블에서 first_name에 대해 12자리의 문자열 자리를 만들되 first_name의 데이터 값이 12자리보다 작으면 왼쪽에서부터 *를 채워서 출력
SELECT first_name, LPAD(first_name, 12, '*')
FROM employees;
LTRIM, RTRIM
- ‘삭제할 문자’ 옵션을 주지 않으면 공백을 제거
예제 : employees 테이블에서 job_id의 데이터 값에 대해 왼쪽 방향부터 ‘F’ 문자를 만나면 삭제하고 또 오른쪽 방향부터 ‘T’문자를 만나면 삭제해보자
SELECT job_id, LTRIM(job_id, 'F'),
RTRIM(job_id, 'T')
FROM employees;
TRIM
- 공백을 제거하는데 사용, 문자열 중간에 있는 공백은 제거 불가
SELECT 'start'||TRIM(' - space - ')||'end'
FROM dual;
💡 “고객 이름”란에 “송민규 “ 라고 입력했을 때 처리하기 유용
2-2. 숫자 타입 함수
: 숫자를 계산하거나 계산이 끝난 후에 추가로 가공 처리를 할 때 사용
- 숫자 타입 함수의 종류
Round : 숫자 반올림하기
ROUND(숫자 or 열 이름, 반올림할 자리 값)
TRUNC : 숫자 절삭하기 (버림)
TRUNC(숫자 or 열 이름, 절삭할 자리 값)
2-3. 날짜 타입 함수
- 날짜에 숫자를 더하거나 빼면 날짜 결과를 출력
- 날짜에서 날짜를 빼면 두 날짜 사이의 일수를 출력
- 날짜에 시간을 더하거나 빼려면 시간을 24로 나누어서 더하거나 뺀다.
날짜 함수의 종류
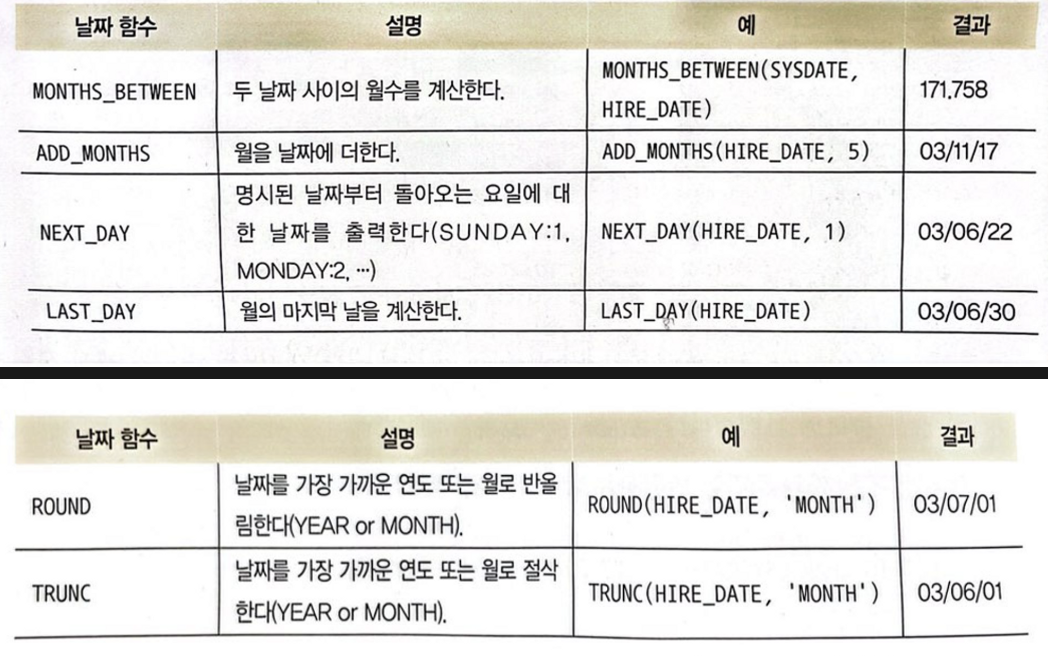
MONTHS_BETWEEN : 두 날짜 사이의 개월 수 계산하기
- ‘날짜’ 부분에는 날짜 데이터 타입의 열 이름을 기술해도 됨
MONTHS_BETWEEN(날짜, 날짜)
예제 : employees 테이블에서 department_id가 100인 직원에 대해 오늘 날짜, hire_date, 오늘 날짜와 hire_date 사이의 개월 수를 출력
SELECT SYSDATE, hire_date, MONTHS_BETWEEN(SYSDATE, hire_date)
FROM employees
WHERE department_id = 100;
ADD_MONTHS : 월에 날짜 더하기
ADD_MONTHS(날짜, 숫자)
예제 : employees 테이블에서 department_id가 100과 106 사이인 직원의 hire_date에 3개월을 더한 값, hire_date에 3개월을 뺀 값을 출력
SELECT hire_date, ADD_MONTHS(hire_date,3), ADD_MONTHS(hire_date,-3)
FROM employees
WHERE department_id BETWEEN 100 AND 106;
NEXT_DAY : 돌아오는 요일의 날짜 계산
- 지정된 요일의 돌아오는 날짜가 언제인지 계산하는 함수
- 일요일 = 1
NEXT_DAY(날짜, '요일' or 숫자)
예제 : employees 테이블에서 department_id가 100과 106 사이인 직원의 hire_date에서 가장 가까운 금요일의 날짜가 언제인지 문자로 지정해서 출력하고, 숫자로도 지정해서 출력
SELECT hire_date, NEXT_DAY(hire_date, '금요일'), NEXT_DAY(hire_date, 6)
FROM employees
WHERE department_id BETWEEN 100 AND 106;
LAST_DAY : 돌아오는 월의 마지막 날짜 계산
LAST_DAY(날짜)
예제 : employees 테이블에서 department_id가 100과 106 사이인 직원의 hire_date를 기준으로 해당 월의 마지막 날짜 출력
SELECT hire_date, LAST_DAY(hire_date) 적용결과
FROM employees
WHERE department_id BETWEEN 100 AND 106;
ROUND, TRUNC : 날짜를 반올림하거나 버림
ROUND or TRUNC(날짜, 지정 값)
💡 기준 날짜(’지정값’)의 하위 단계에서 따져보는 것이 이해하기 쉬움
예제 : employees 테이블에서 department_id가 100과 106 사이인 직원의 hire_date에 대해 월 기준 반올림, 연 기준 반올림, 월 기준 절삭, 연 기준 절삭을 적용해 출력
SELECT hire_date,
ROUND(hire_date, 'MONTH'),
ROUND(hire_date, 'YEAR'),
TRUNC(hire_date, 'MONTH'),
TRUNC(hire_date, 'YEAR')
FROM employees
WHERE department_id BETWEEN 100 AND 106;
2-4. 변환 함수
자동 데이터 타입 변환
FROM TO
| VARCHAR2 혹은 CHAR | NUMBER(숫자) |
| VARCHAR2 혹은 CHAR | DATE(날짜) |
| NUMBER | VARCHAR2(문자) |
| DATE | VARCHAR2(문자) |
SELECT 1 + '2'
FROM DUAL;
수동 데이터 타입 변환
함수 설명
| TO_CHAR | 숫자, 문자, 날짜 값을 지정 형식의 VARCHAR2 타입으로 변환 |
| TO_NUMBER | 문자를 숫자 타입으로 변환 |
| TO_DATE | 날짜를 나타내는 문자열을 지정 형식의 날짜 타입으로 변환 |
날짜 및 시간 형식 변환하기
TO_CHAR
TO_CHAR(날짜 데이터 타입, '지정 형식')
- 날짜 지정 형식
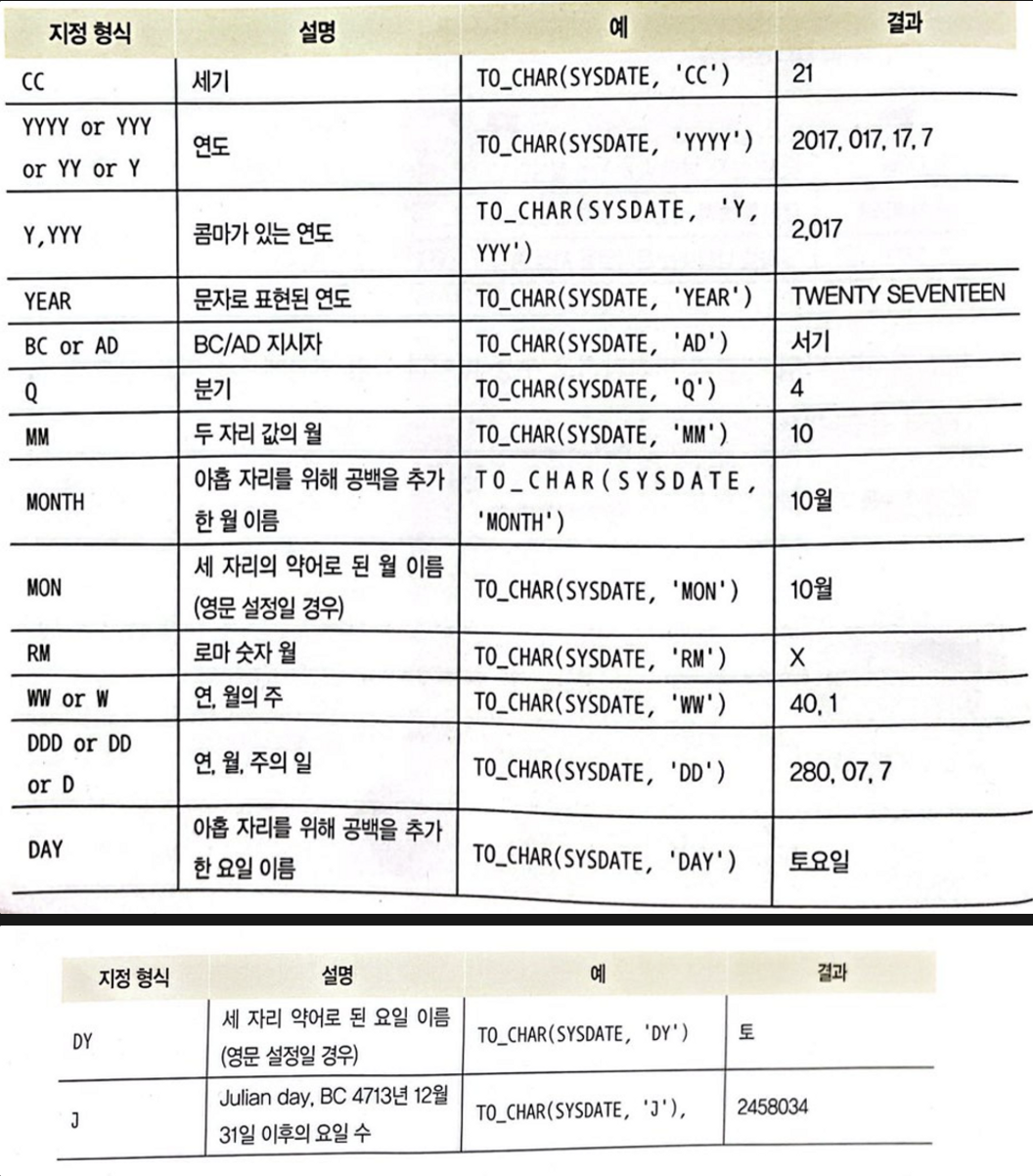
- 시간 지정 형식
지정 형식 설명
| AM or PM | 오전 또는 오후 표시 |
| HH / HH12 or HH24 | 시간 표현 |
| MI | 분(0~59) |
| SS | ch(0~59) |
예시
SELECT TO_CHAR(SYSDATE, 'HH:MI:SS PM'),
TO_CHAR(SYSDATE, 'YYYY/MM/DD HH:MI:SS PM')
FROM dual;
- 기타 형식
요소 설명
| / . - | 사용 문자를 출력 결과에 표현 |
| “문자” | 큰따옴표 안의 문자를 출력 결과에 표현 |
숫자 형식 변환하기
TO_CHAR
TO_CHAR(숫자 데이터 타입, '지정 형식')
TO_NUMBER
TO_NUMBER(number)
TO_DATE
TO_DATE(문자열, '지정 형식')
2-5. 일반 함수
NVL : NULL 값 처리하기
- null 값을 포함하는 산술 연산의 결과는 null
NVL(열 이름, 치환 값)
예제 : employees 테이블에서 salary에 commission_pct를 곱하되 commission_pct가 null일 때는 1로 치환하여 commission_pct를 곱한 결과를 출력
SELECT salary * NVL(commission_pct,1)
FROM employees
ORDER BY commission_pct;
DECODE : 조건 논리 처리하기
DECODE(열 이름, 조건 값, 치환 값, 기본값)
예제 : employees 테이블에서 first_name, last_name, department_id, salary를 출력하되 department_id가 60인 경우에는 급여를 10% 인상한 값을 계산하여 출력하고 나머지 경우에는 원래의 값을 출력, department_id가 60인 경우에는 ‘10%인상’을 출력하고 나머지 경우에는 ‘미인상’을 출력
SELECT first_name,
last_name,
DECODE(department_id, 60, salary*1.1, salary),
DECODE(department_id, 60, '10%인상', '미인상')
FROM employees;
CASE 표현식 : 복잡한 조건 논리 처리하기
CASE
WHEN 조건1 THEN 출력값1
WHEN 조건2 THEN 출력값2
...
ELSE 출력값3
END
예제 : employees 테이블에서 job_id가 IT_PROG라면 employee_id, first_name, last_name, salary를 출력하되 salary가 9000 이상이면 ‘상위급여’, 6000과 8999 사이면 ‘중위급여’, 그 외는 ‘하위급여’라고 출력
SELECT employee_id, first_name, last_name, salary,
CASE
WHEN salary >= 9000 THEN '상위급여'
WHEN salary BETWEEN 6000 AND 8999 THEN '중위급여'
ELSE '하위급여'
END AS 급여등급
FROM employees
WHERE job_id = 'IT_PROG';
RANK, DENSE_RANK, ROW_NUMBER : 데이터 값에 순위 매기기
함수 설명 순위 예
| RANK | 공통 순위를 출력하되 공통 순위만큼 건너뛰어 다음 순위를 출력 | 1,2,2,4,… |
| DENSE_RANK | 공통 순위를 출력하되 건너뛰지 않고 바로 다음 순위를 출력 | 1,2,2,3,… |
| ROW_NUMBER | 공통 순위 없이 출력 | 1,2,3,4,… |
RANK() OVER([PARTITION BY 열 이름] ORDER BY 열 이름)
💡 PARTITION BY절은 전체를 어떤 기준으로 그룹화 할 때 사용
예제 : RANK, DENSE_RANK, ROW_NUMBER 함수를 각각 이용해 employees 테이블의 salary 값이 높은 순서대로 순위를 매겨 출력
SELECT employee_id,
salary,
RANK() OVER(ORDER BY salary DESC) RANK_급여,
DENSE_RANK() OVER(ORDER BY salary DESC) DENSE_RANK_급여,
ROW_NUMBER() OVER(ORDER BY salary DESC) ROW_RANK_급여
FROM employees;
3. 그룹 함수 : 그룹으로 요약하기
- 여러 행에 대해 함수가 적용되어 하나의 결과를 나타내는 함수
- GROUP BY 절을 이용하여 처리
3-1. 그룹 함수의 종류와 사용법
**SELECT** **그룹함수(열 이름)**
**FROM** **테이블이름**
[WHERE 조건식]
[ORDER BY 열이름];
함수 설명 예 null 처리
| COUNT | 행 개수를 셈 | COUNT(salary) | (*)의 경우 null 값도 개수로 셈 |
| SUM | 합계 | SUM(salary) | null 값을 제외하고 연산 |
| AVG | 평균 | AVG(salary) | null 값을 제외하고 연산 |
| MAX | 최댓값 | MAX(salary) | null 값을 제외하고 연산 |
| MIN | 최솟값 | MIN(salary) | null 값을 제외하고 연산 |
| STDDEV | 표준편차 | STDDEV(salary) | null 값을 제외하고 연산 |
| VARIANCE | 분산 | VARIANCE(salary) | null 값을 제외하고 연산 |
COUNT 함수
- 지정된 열의 행 개수를 세는 함수
- 유의 : null도 count 한다.
COUNT(열 이름)
예제 : employees 테이블에서 salary의 행 수가 몇 개인지 출력
SELECT COUNT(salary)
FROM employees;
SUM,AVG 함수
- SUM : 열의 합계를 구하는 함수
- AVG : 열의 평균을 구하는 함수
SUM(열 이름) / AVG(열 이름)
예제 : employees 테이블에서 salary의 합계와 평균을 구해보자. 또한 AVG 함수 사용하지 말고 평균을 구해보자
SELECT SUM(salary), AVG(salary), SUM(salary)/COUNT(salary)
FROM employees;
MAX, MIN 함수
MAX(열 이름) / MIN(열 이름)
예제 : employees 테이블에서 salary의 최댓값, 최솟값을 출력
SELECT MAX(salary), MIN(salary)
FROM employees;
3-2. GROUP BY : 그룹으로 묶기
- 기준 열을 지정하여 그룹화하는 명령어
SELECT 기준 열, 그룹 함수(열 이름)
FROM 테이블 이름
[WHERE 조건식]
GROUP BY 열 이름
[ORDER BY 열 이름];
논리 순서
- FROM : 테이블에 접근
- WHERE : 조건식에 맞는 데이터 값만 골라냄
- GROUP BY : 기술된 기준 열을 기준으로 같은 데이터 값끼리 그룹화한다
- SELECT : 결과 출력
- ORDER BY : 오름차순 or 내림차순으로 정렬
GROUP BY 특징
- SELECT 절에 기준 열과 그룹 함수가 같이 지정되면 GROUP BY 절에 기준 열 이름이 반드시 기술되어야 함
- SELECT 절에 그룹 함수만 기술되고 열 이름이 기술되지 않으면 GROUP BY 절을 반드시 기술할 필요X
- WHERE 절을 사용하면 행을 그룹으로 묶기 전에 앞서 조건식이 적용됨
- SELECT 절에 그룹 함수를 사용하지 않아도 GROUP BY 절만으로도 사용 가능
예제 : employees 테이블에서 employee_id가 10 이상인 직원에 대해 job_id별로 그룹화하여 job_id별 총 급여와 job_id별 평균 급여를 구하고, job_id별 총 급여를 기준으로 내림차순으로 정렬
SELECT job_id, SUM(salary) 총급여, AVG(salary) 평균급여
FROM employees
WHERE employee_id >= 10;
GROUP BY job_id
ORDER BY 총급여 DESC, 평균급여;
- 그룹에 대한 그룹
SELECT job_id job_id_대그룹,
manager_id manager_id_중그룹,
SUM(salary) 총급여,
AVG(salary) 평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY job_id, manager_id << job_id별로 그룹화 뒤, manager_id별로 다시 그룹화
ORDER BY 총급여 DESC, 평균급여;
3-3. HAVING : 연산된 그룹 함수 결과에 조건 적용하기
- HAVING 절은 그룹화된 값에 조건식을 적용할 때 사용
- WHERE 절에서는 그룹함수를 사용할 수 없으므로, HAVING 절을 사용해 그룹 함수의 결괏값에 대해 조건식을 적용
SELECT 열 이름, 그룹 함수(열 이름)
FROM 테이블 이름
[WHERE 조건식]
GROUP BY 열 이름
[HAVING 조건식]
[ORDER BY 열 이름];
💡 논리 순서는 GROUP BY 다음이다.
'CS > DataBase' 카테고리의 다른 글
| [DB] 제 3 정규화 vs BCNF (0) | 2023.05.29 |
|---|---|
| 관계대수에서 assignment 과 rename의 차이? (0) | 2023.03.14 |
| WHERE 조건 절을 활용한 데이터 검색 (1) | 2023.03.14 |
| SELECT 문의 기본 문법 (0) | 2023.03.14 |
| SQL 용어 정리 (0) | 2023.03.14 |


댓글